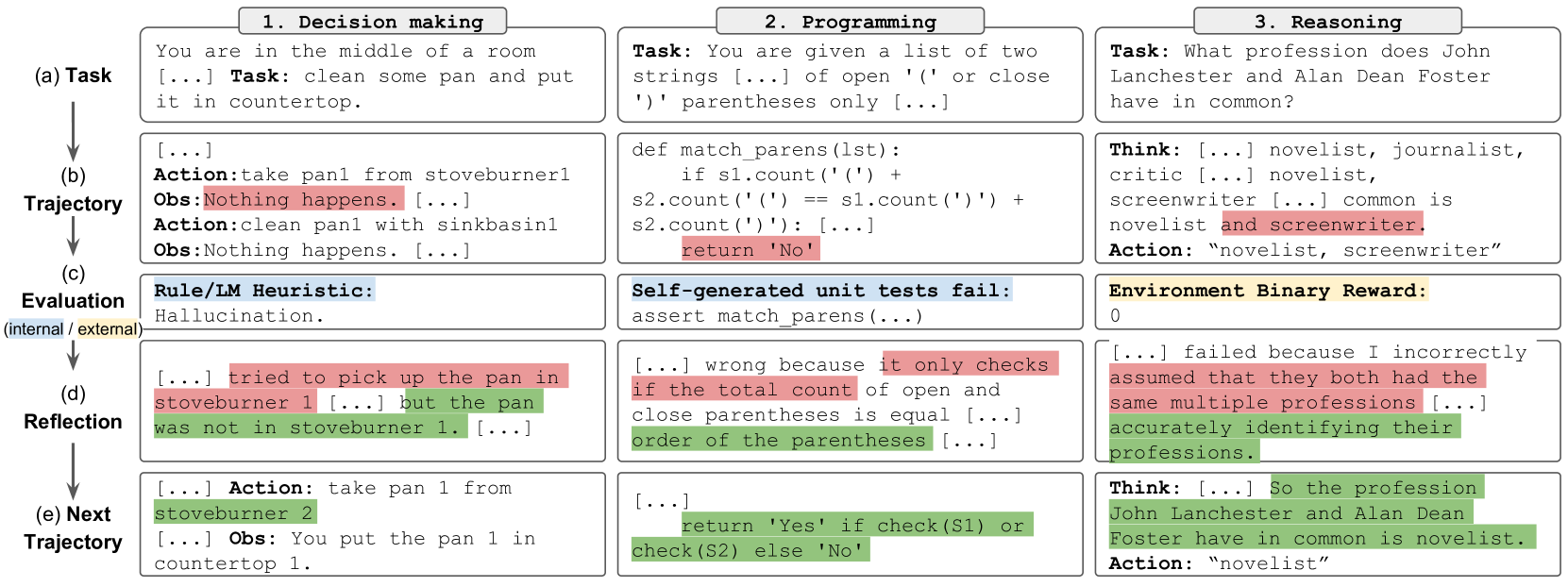
# Technical Document Extraction: AI Agent Self-Correction Framework
This image illustrates a comparative workflow for AI agent self-correction across three distinct domains: **Decision making**, **Programming**, and **Reasoning**. The diagram is structured as a grid with five sequential stages (rows) and three task categories (columns).
## 1. Structural Overview
### Vertical Axis (Stages of the Process)
The process flows downward through five labeled stages:
* **(a) Task**: The initial prompt or goal.
* **(b) Trajectory**: The agent's initial attempt or execution path.
* **(c) Evaluation (internal / external)**: The mechanism used to identify errors.
* **(d) Reflection**: The agent's analysis of what went wrong.
* **(e) Next Trajectory**: The corrected action or output based on reflection.
### Horizontal Axis (Task Domains)
1. **Decision making** (e.g., embodied AI/robotics)
2. **Programming** (e.g., code generation)
3. **Reasoning** (e.g., multi-hop question answering)
---
## 2. Detailed Content Extraction
### Column 1: Decision making
* **(a) Task**: "You are in the middle of a room [...] **Task:** clean some pan and put it in countertop."
* **(b) Trajectory**:
* `Action: take pan1 from stoveburner1`
* `Obs: Nothing happens. [...]` (Highlighted in red)
* `Action: clean pan1 with sinkbasin1`
* `Obs: Nothing happens. [...]`
* **(c) Evaluation**: **Rule/LM Heuristic:** (Blue highlight) "Hallucination."
* **(d) Reflection**: "[...] tried to pick up the pan in stoveburner 1 [...]" (Red highlight) "but the pan was not in stoveburner 1. [...]" (Green highlight)
* **(e) Next Trajectory**: "[...] **Action:** take pan 1 from stoveburner 2" (Green highlight) "[...] **Obs:** You put the pan 1 in countertop 1."
### Column 2: Programming
* **(a) Task**: "**Task:** You are given a list of two strings [...] of open '(' or close ')' parentheses only [...]"
* **(b) Trajectory**:
* `def match_parens(lst):`
* `if s1.count('(') + s2.count('(') == s1.count(')') + s2.count(')'): [...]`
* `return 'No'` (Highlighted in red)
* **(c) Evaluation**: **Self-generated unit tests fail:** (Blue highlight) `assert match_parens(...)`
* **(d) Reflection**: "[...] wrong because it only checks if the total count of open and close parentheses is equal [...]" (Red highlight) "order of the parentheses [...]" (Green highlight)
* **(e) Next Trajectory**: "[...] return 'Yes' if check(S1) or check(S2) else 'No'" (Green highlight)
### Column 3: Reasoning
* **(a) Task**: "**Task:** What profession does John Lanchester and Alan Dean Foster have in common?"
* **(b) Trajectory**:
* `Think: [...] novelist, journalist, critic [...] novelist, screenwriter [...] common is novelist and screenwriter.` (Red highlight)
* `Action: "novelist, screenwriter"`
* **(c) Evaluation**: **Environment Binary Reward:** (Yellow highlight) `0`
* **(d) Reflection**: "[...] failed because I incorrectly assumed that they both had the same multiple professions [...]" (Red highlight) "accurately identifying their professions." (Green highlight)
* **(e) Next Trajectory**:
* `Think: [...] So the profession John Lanchester and Alan Dean Foster have in common is novelist.` (Green highlight)
* `Action: "novelist"`
---
## 3. Visual Coding & Legend Analysis
The diagram uses color-coded highlights to indicate the status of information:
* **Red Highlights**: Indicate errors, incorrect assumptions, or failed outputs in the initial trajectory and reflection.
* **Green Highlights**: Indicate corrections, accurate observations, or successful outputs in the reflection and next trajectory.
* **Blue Highlights (Evaluation Row)**: Represent internal evaluation methods (Heuristics or Self-generated tests).
* **Yellow Highlight (Evaluation Row)**: Represents an external evaluation method (Environment Reward).
## 4. Flow Summary
The diagram demonstrates that regardless of the domain, the self-correction loop follows a consistent pattern: an initial **Task** leads to a flawed **Trajectory**. An **Evaluation** (either internal logic or external feedback) triggers a **Reflection** where the agent identifies the specific error (Red) and determines the correction (Green). This results in a successful **Next Trajectory**.