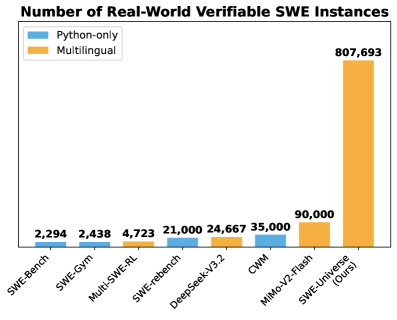
## Bar Chart: Number of Real-World Verifiable SWE Instances
### Overview
The image is a bar chart comparing the number of real-world verifiable SWE (Software Weakness Enumeration) instances across different benchmarks and models. The chart compares "Python-only" instances against "Multilingual" instances. The x-axis represents the different SWE benchmarks/models, and the y-axis represents the number of instances.
### Components/Axes
* **Title:** Number of Real-World Verifiable SWE Instances
* **X-axis:** Categorical labels for different SWE benchmarks/models: SWE-Bench, SWE-Gym, Multi-SWE-RL, SWE-rebench, DeepSeek-V3.2, CWM, MiMo-V2-Flash, SWE-Universe (Ours)
* **Y-axis:** (Implicit) Number of instances. The values are displayed above each bar.
* **Legend:** Located in the top-left corner.
* Blue: Python-only
* Orange: Multilingual
### Detailed Analysis
The chart presents the number of verifiable SWE instances for each benchmark/model, separated by Python-only and Multilingual.
* **SWE-Bench:** Python-only: 2,294
* **SWE-Gym:** Python-only: 2,438
* **Multi-SWE-RL:** Multilingual: 4,723
* **SWE-rebench:** Python-only: 21,000
* **DeepSeek-V3.2:** Python-only: 24,667
* **CWM:** Python-only: 35,000
* **MiMo-V2-Flash:** Multilingual: 90,000
* **SWE-Universe (Ours):** Multilingual: 807,693
### Key Observations
* SWE-Universe (Ours) has a significantly higher number of multilingual instances (807,693) compared to all other benchmarks/models.
* The number of Python-only instances varies across different benchmarks, ranging from 2,294 (SWE-Bench) to 35,000 (CWM).
* Multi-SWE-RL and MiMo-V2-Flash only have Multilingual instances reported.
### Interpretation
The chart highlights the performance of different benchmarks/models in terms of the number of verifiable SWE instances. The SWE-Universe (Ours) model demonstrates a substantially higher number of multilingual instances, suggesting it is more effective at identifying weaknesses in multilingual code compared to the other benchmarks/models. The data also shows the distribution of Python-only instances across different benchmarks, providing insights into their performance on Python-specific code. The large difference in the number of instances between SWE-Universe and other models suggests a significant improvement or difference in methodology.