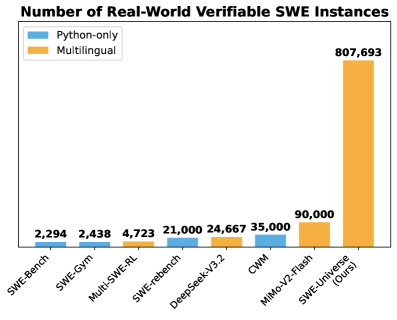
## Bar Chart: Number of Real-World Verifiable SWE Instances
### Overview
This is a vertical bar chart comparing the number of verifiable Software Engineering (SWE) instances across different benchmarks or datasets. The chart highlights two categories of instances: "Python-only" and "Multilingual." The primary takeaway is the significantly larger scale of the "SWE-Universal (Ours)" dataset compared to all others listed.
### Components/Axes
* **Chart Title:** "Number of Real-World Verifiable SWE Instances"
* **Legend:** Located in the top-left corner.
* **Blue Square:** "Python-only"
* **Orange Square:** "Multilingual"
* **X-Axis (Categories):** Lists eight different benchmarks/datasets. From left to right:
1. SWE-Bench
2. SWE-Gym
3. Multi-SWE-RL
4. SWE-rebench
5. DeepSeek-V3.2
6. QWM
7. MIMO-V2-Flash
8. SWE-Universal (Ours)
* **Y-Axis:** Represents the count of instances. The axis line is present, but no numerical labels or title are visible. Values are provided directly above each bar.
* **Data Labels:** Exact numerical values are printed above each bar.
### Detailed Analysis
The chart presents the following data points for each category:
1. **SWE-Bench:**
* **Bar:** Single blue bar (Python-only).
* **Value:** 2,294.
* **Trend:** Baseline value, the smallest on the chart.
2. **SWE-Gym:**
* **Bar:** Single blue bar (Python-only).
* **Value:** 2,438.
* **Trend:** Slightly higher than SWE-Bench.
3. **Multi-SWE-RL:**
* **Bar:** Single orange bar (Multilingual).
* **Value:** 4,723.
* **Trend:** First multilingual entry, roughly double the preceding Python-only values.
4. **SWE-rebench:**
* **Bar:** Single blue bar (Python-only).
* **Value:** 21,000.
* **Trend:** Significant jump in scale compared to previous entries.
5. **DeepSeek-V3.2:**
* **Bar:** Single orange bar (Multilingual).
* **Value:** 24,667.
* **Trend:** Comparable in scale to SWE-rebench, but multilingual.
6. **QWM:**
* **Bar:** Single blue bar (Python-only).
* **Value:** 35,000.
* **Trend:** The largest Python-only dataset shown.
7. **MIMO-V2-Flash:**
* **Bar:** Single orange bar (Multilingual).
* **Value:** 90,000.
* **Trend:** A major increase, more than double the previous highest value (QWM).
8. **SWE-Universal (Ours):**
* **Bar:** Single orange bar (Multilingual).
* **Value:** 807,693.
* **Trend:** An order-of-magnitude increase over all other datasets. This bar dominates the chart visually.
### Key Observations
* **Scale Disparity:** The "SWE-Universal (Ours)" dataset contains approximately **9 times** more instances than the next largest dataset (MIMO-V2-Flash) and over **350 times** more than the smallest (SWE-Bench).
* **Category Distribution:** Of the eight datasets listed, five are categorized as "Python-only" (blue) and three as "Multilingual" (orange). The two largest datasets by a wide margin are both multilingual.
* **Visual Trend:** There is a general, non-linear upward trend in dataset size from left to right, culminating in the massive final bar. The growth is not monotonic, as the fourth bar (SWE-rebench) is smaller than the fifth (DeepSeek-V3.2).
### Interpretation
This chart is likely from a research paper or technical report introducing the "SWE-Universal" dataset. Its primary purpose is to **demonstrate the unprecedented scale** of this new resource compared to existing benchmarks in the software engineering domain.
* **What the data suggests:** The field has previously relied on relatively small, often language-specific (Python) datasets for training and evaluating AI models on real-world software tasks. "SWE-Universal" represents a massive leap in available verifiable data, specifically emphasizing multilingual support.
* **How elements relate:** The x-axis orders the datasets, likely in a combination of chronological release and increasing scale, to build a narrative of progression that peaks with the authors' contribution. The color coding (blue vs. orange) immediately draws a distinction between language-specific and broader multilingual resources.
* **Notable implications:** The sheer size of "SWE-Universal" implies it could enable the training of more robust and generalizable AI software engineering agents. The emphasis on "verifiable" instances suggests a focus on high-quality, ground-truth data where the correctness of solutions can be automatically checked, which is crucial for reliable benchmarking. The chart makes a compelling visual argument for the significance of the authors' work.