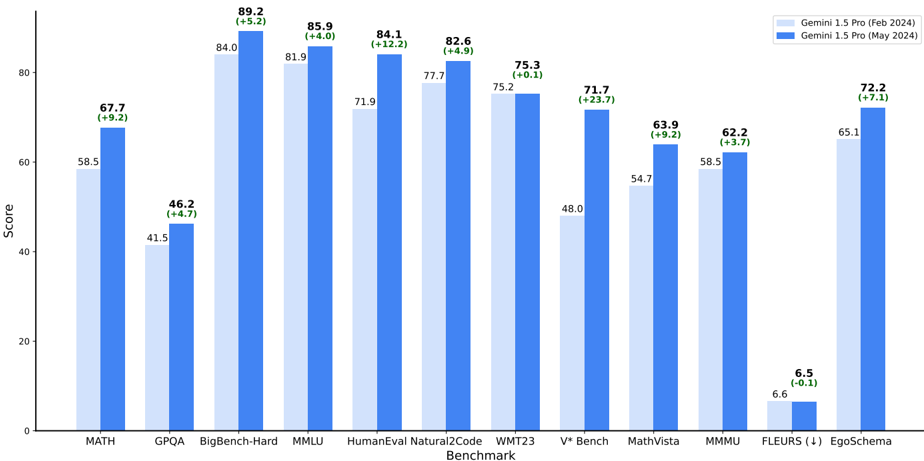
## Bar Chart: Gemini 1.5 vs. Gemini 1.5 Pro Benchmark Scores
### Overview
This bar chart compares the performance of two language models, Gemini 1.5 (February 2024) and Gemini 1.5 Pro (May 2024), across a range of benchmarks. The chart displays the scores achieved by each model on each benchmark, using blue bars. Each bar is paired with a value indicating the change in score from Gemini 1.5 to Gemini 1.5 Pro.
### Components/Axes
* **X-axis:** Benchmark Name (MATH, GPQA, BigBench-Hard, MMLU, HumanEval, Natural2Code, WMT23, V\* Bench, MathVista, MMU, FLEURS (!), EgoSchema)
* **Y-axis:** Score (ranging from 0 to 80, with increments of 10)
* **Legend:**
* Gemini 1.5 (Feb 2024) - Light Blue
* Gemini 1.5 Pro (May 2024) - Dark Blue
* **Data Series:** Two bar series representing the scores for each model on each benchmark.
* **Change in Score:** Displayed above each pair of bars, indicating the difference between Gemini 1.5 Pro and Gemini 1.5 scores.
### Detailed Analysis
Here's a breakdown of the scores for each benchmark, with the change in score from Gemini 1.5 to Gemini 1.5 Pro:
* **MATH:** Gemini 1.5: 58.5, Gemini 1.5 Pro: 67.7 (+9.2)
* **GPQA:** Gemini 1.5: 41.5, Gemini 1.5 Pro: 46.2 (+4.7)
* **BigBench-Hard:** Gemini 1.5: 84.0, Gemini 1.5 Pro: 89.2 (+5.2)
* **MMLU:** Gemini 1.5: 81.9, Gemini 1.5 Pro: 85.9 (+4.0)
* **HumanEval:** Gemini 1.5: 71.9, Gemini 1.5 Pro: 84.1 (+12.2)
* **Natural2Code:** Gemini 1.5: 77.7, Gemini 1.5 Pro: 82.6 (+4.9)
* **WMT23:** Gemini 1.5: 75.2, Gemini 1.5 Pro: 75.3 (+0.1)
* **V\* Bench:** Gemini 1.5: 48.0, Gemini 1.5 Pro: 71.7 (+23.7)
* **MathVista:** Gemini 1.5: 54.7, Gemini 1.5 Pro: 63.9 (+9.2)
* **MMU:** Gemini 1.5: 58.5, Gemini 1.5 Pro: 62.2 (+3.7)
* **FLEURS (!):** Gemini 1.5: 6.6, Gemini 1.5 Pro: 6.5 (-0.1)
* **EgoSchema:** Gemini 1.5: 65.1, Gemini 1.5 Pro: 72.2 (+7.1)
**Trend Verification:**
Generally, the dark blue bars (Gemini 1.5 Pro) are taller than the light blue bars (Gemini 1.5), indicating improved performance. The magnitude of the difference varies across benchmarks.
### Key Observations
* **Largest Improvement:** The most significant performance gain for Gemini 1.5 Pro is observed on the V\* Bench (+23.7).
* **Slight Regression:** Gemini 1.5 Pro shows a slight regression on the FLEURS (!) benchmark (-0.1).
* **Consistent Gains:** Gemini 1.5 Pro consistently outperforms Gemini 1.5 across most benchmarks.
* **High Scores:** Both models achieve relatively high scores on benchmarks like BigBench-Hard, MMLU, and HumanEval.
### Interpretation
The data demonstrates that Gemini 1.5 Pro represents a substantial improvement over Gemini 1.5 across a wide range of benchmarks. The largest gains are seen in areas like V\* Bench, suggesting improvements in reasoning and problem-solving capabilities. The slight regression on FLEURS (!) might indicate a specific weakness in that area, or simply a statistical fluctuation. The consistent gains across most benchmarks suggest a general improvement in the model's overall performance. The benchmarks cover a diverse set of tasks, including mathematical reasoning (MATH, MathVista), question answering (GPQA), multiple-choice questions (MMLU), code generation (HumanEval, Natural2Code), machine translation (WMT23), and commonsense reasoning (EgoSchema). This broad improvement suggests that the updates to the model have had a positive impact on its capabilities across various domains. The inclusion of the change in score provides a clear and concise way to quantify the improvement for each benchmark.