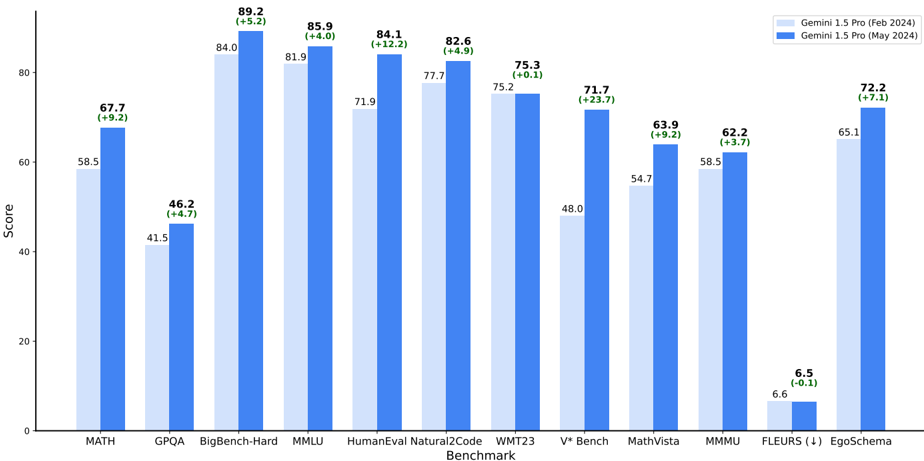
## Bar Chart: Gemini 1.5 Pro Performance Comparison (Feb vs May 2024)
### Overview
The chart compares performance scores of Gemini 1.5 Pro across 12 technical benchmarks between February 2024 and May 2024. Two data series are shown: light blue (Feb 2024) and dark blue (May 2024), with percentage improvements noted above each bar.
### Components/Axes
- **X-axis**: Benchmark categories (MATH, GPQA, BigBench-Hard, MMLU, HumanEval Natural2Code, WMT23, V* Bench, MathVista, MMMU, FLEURS (1), EgoSchema)
- **Y-axis**: Score scale (0–100)
- **Legend**:
- Light blue: Gemini 1.5 Pro (Feb 2024)
- Dark blue: Gemini 1.5 Pro (May 2024)
- **Text annotations**: Percentage changes (+X.X%) above each bar
### Detailed Analysis
1. **MATH**: 58.5 (Feb) → 67.7 (May) (+9.2%)
2. **GPQA**: 41.5 (Feb) → 46.2 (May) (+4.7%)
3. **BigBench-Hard**: 84.0 (Feb) → 89.2 (May) (+5.2%)
4. **MMLU**: 81.9 (Feb) → 85.9 (May) (+4.0%)
5. **HumanEval Natural2Code**: 71.9 (Feb) → 84.1 (May) (+12.2%)
6. **WMT23**: 75.2 (Feb) → 75.3 (May) (+0.1%)
7. **V* Bench**: 48.0 (Feb) → 71.7 (May) (+23.7%)
8. **MathVista**: 54.7 (Feb) → 63.9 (May) (+9.2%)
9. **MMMU**: 58.5 (Feb) → 62.2 (May) (+3.7%)
10. **FLEURS (1)**: 6.6 (Feb) → 6.5 (May) (-0.1%)
11. **EgoSchema**: 65.1 (Feb) → 72.2 (May) (+7.1%)
### Key Observations
- **Highest improvement**: V* Bench (+23.7%) and HumanEval Natural2Code (+12.2%)
- **Most stable performance**: WMT23 (0.1% change)
- **Only decline**: FLEURS (1) (-0.1%)
- **Consistent gains**: 10/11 benchmarks improved, with 7 showing >5% growth
- **Score range**: FLEURS (1) lowest (6.5) → BigBench-Hard highest (89.2)
### Interpretation
The data demonstrates systematic performance improvements across most technical domains in the May 2024 release. The largest gains in code generation (HumanEval) and multi-modal reasoning (V* Bench) suggest targeted architectural or training optimizations. The near-perfect stability in WMT23 indicates maintained linguistic capabilities. The slight decline in FLEURS (1) warrants investigation, though its low baseline score suggests limited impact on overall performance. The 7.1% improvement in EgoSchema highlights progress in embodied reasoning tasks. Overall, the May 2024 version shows a 5.2–23.7% relative improvement across critical AI benchmarks, positioning it as a significant upgrade from the February release.