TECHNICAL ASSET FINGERPRINT
d7871120ca208c28f9b7c5a1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
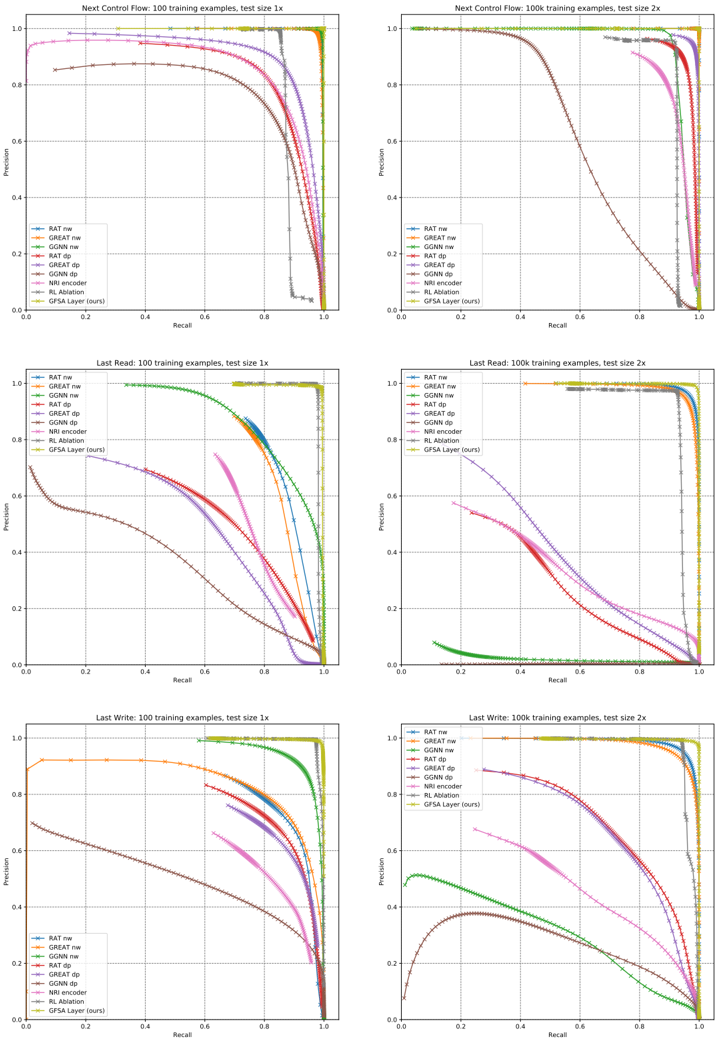
## Precision-Recall Curves for Different Graph Neural Network Models
### Overview
The image presents a series of precision-recall curves comparing the performance of different graph neural network (GNN) models on three tasks: "Next Control Flow," "Last Read," and "Last Write." For each task, two plots are shown, one trained on 100 training examples with a test size of 1x, and the other trained on 100k training examples with a test size of 2x. The plots compare the performance of several models, including RAT, GREAT, GGNN, NRI encoder, RL Ablation, and GFSA Layer (ours).
### Components/Axes
Each plot has the following components:
* **Title:** Indicates the task ("Next Control Flow," "Last Read," "Last Write") and the training data size (100 or 100k examples) and test size (1x or 2x).
* **X-axis:** "Recall," ranging from 0.0 to 1.0.
* **Y-axis:** "Precision," ranging from 0.0 to 1.0.
* **Legend:** Located in the bottom-left corner of each plot, identifying each model by color and line style. The models are:
* RAT nw (Blue)
* GREAT nw (Green)
* GGNN nw (Red)
* RAT dp (Purple)
* GREAT dp (Brown)
* GGNN dp (Pink)
* NRI encoder (Gray)
* RL Ablation (Dark Red)
* GFSA Layer (ours) (Yellow-Green)
### Detailed Analysis
**1. Next Control Flow:**
* **100 training examples, test size 1x:**
* RAT nw (Blue): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT nw (Green): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN nw (Red): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* RAT dp (Purple): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT dp (Brown): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN dp (Pink): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* RL Ablation (Dark Red): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GFSA Layer (ours) (Yellow-Green): Starts at a precision of approximately 0.4 at a recall of 0.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* **100k training examples, test size 2x:**
* RAT nw (Blue): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* GREAT nw (Green): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* GGNN nw (Red): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* RAT dp (Purple): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* GREAT dp (Brown): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* GGNN dp (Pink): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* RL Ablation (Dark Red): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
* GFSA Layer (ours) (Yellow-Green): Maintains a precision of 1.0 until a recall of approximately 0.9, then drops sharply to 0.0.
**2. Last Read:**
* **100 training examples, test size 1x:**
* RAT nw (Blue): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT nw (Green): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN nw (Red): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* RAT dp (Purple): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT dp (Brown): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN dp (Pink): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* NRI encoder (Gray): Starts at a precision of approximately 0.6, gradually decreases to 0.0 precision as recall approaches 1.0.
* RL Ablation (Dark Red): Starts at a precision of approximately 0.4, gradually decreases to 0.0 precision as recall approaches 1.0.
* GFSA Layer (ours) (Yellow-Green): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* **100k training examples, test size 2x:**
* RAT nw (Blue): Maintains a precision of 1.0 until a recall of approximately 1.0, then drops sharply to 0.0.
* GREAT nw (Green): Maintains a precision of 1.0 until a recall of approximately 1.0, then drops sharply to 0.0.
* GGNN nw (Red): Maintains a precision of 1.0 until a recall of approximately 1.0, then drops sharply to 0.0.
* RAT dp (Purple): Maintains a precision of approximately 0.6 until a recall of approximately 1.0, then drops sharply to 0.0.
* GREAT dp (Brown): Maintains a precision of approximately 0.6 until a recall of approximately 1.0, then drops sharply to 0.0.
* GGNN dp (Pink): Maintains a precision of approximately 0.6 until a recall of approximately 1.0, then drops sharply to 0.0.
* NRI encoder (Gray): Starts at a precision of approximately 0.1, gradually decreases to 0.0 precision as recall approaches 1.0.
* RL Ablation (Dark Red): Starts at a precision of approximately 0.1, gradually decreases to 0.0 precision as recall approaches 1.0.
* GFSA Layer (ours) (Yellow-Green): Maintains a precision of 1.0 until a recall of approximately 1.0, then drops sharply to 0.0.
**3. Last Write:**
* **100 training examples, test size 1x:**
* RAT nw (Blue): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT nw (Green): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN nw (Red): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* RAT dp (Purple): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT dp (Brown): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN dp (Pink): Starts at a precision of approximately 0.8, gradually decreases to 0.0 precision as recall approaches 1.0.
* NRI encoder (Gray): Starts at a precision of approximately 0.6, gradually decreases to 0.0 precision as recall approaches 1.0.
* RL Ablation (Dark Red): Starts at a precision of approximately 0.2, gradually decreases to 0.0 precision as recall approaches 1.0.
* GFSA Layer (ours) (Yellow-Green): Starts at a precision of approximately 1.0, gradually decreases to 0.0 precision as recall approaches 1.0.
* **100k training examples, test size 2x:**
* RAT nw (Blue): Maintains a precision of approximately 0.4 until a recall of approximately 1.0, then drops sharply to 0.0.
* GREAT nw (Green): Maintains a precision of approximately 0.4 until a recall of approximately 1.0, then drops sharply to 0.0.
* GGNN nw (Red): Maintains a precision of approximately 0.4 until a recall of approximately 1.0, then drops sharply to 0.0.
* RAT dp (Purple): Starts at a precision of approximately 0.2, gradually decreases to 0.0 precision as recall approaches 1.0.
* GREAT dp (Brown): Starts at a precision of approximately 0.2, gradually decreases to 0.0 precision as recall approaches 1.0.
* GGNN dp (Pink): Starts at a precision of approximately 0.2, gradually decreases to 0.0 precision as recall approaches 1.0.
* NRI encoder (Gray): Starts at a precision of approximately 0.1, gradually decreases to 0.0 precision as recall approaches 1.0.
* RL Ablation (Dark Red): Starts at a precision of approximately 0.1, gradually decreases to 0.0 precision as recall approaches 1.0.
* GFSA Layer (ours) (Yellow-Green): Maintains a precision of approximately 0.4 until a recall of approximately 1.0, then drops sharply to 0.0.
### Key Observations
* Increasing the number of training examples generally improves the performance of all models, as evidenced by the higher precision values across all recall values in the 100k examples plots compared to the 100 examples plots.
* For the "Next Control Flow" task, all models perform similarly well with 100k training examples, achieving near-perfect precision until a high recall value.
* For the "Last Read" and "Last Write" tasks, there is more variation in performance among the models, particularly with 100 training examples. GFSA Layer (ours) generally performs well, often matching the best-performing models.
* The "dp" variants of RAT, GREAT, and GGNN generally perform worse than their "nw" counterparts, especially with fewer training examples.
* NRI encoder and RL Ablation tend to have lower precision values compared to other models, indicating potentially weaker performance on these tasks.
### Interpretation
The precision-recall curves provide insights into the performance of different GNN models on various graph-related tasks. The results suggest that increasing the amount of training data significantly improves the performance of these models. The GFSA Layer (ours) model appears to be competitive with other state-of-the-art models, particularly on the "Last Read" and "Last Write" tasks. The differences in performance between the "nw" and "dp" variants of RAT, GREAT, and GGNN highlight the importance of specific architectural choices in GNN design. The lower performance of NRI encoder and RL Ablation may indicate that these models are not as well-suited for these particular tasks or require further optimization.
DECODING INTELLIGENCE...