TECHNICAL ASSET FINGERPRINT
d7871120ca208c28f9b7c5a1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
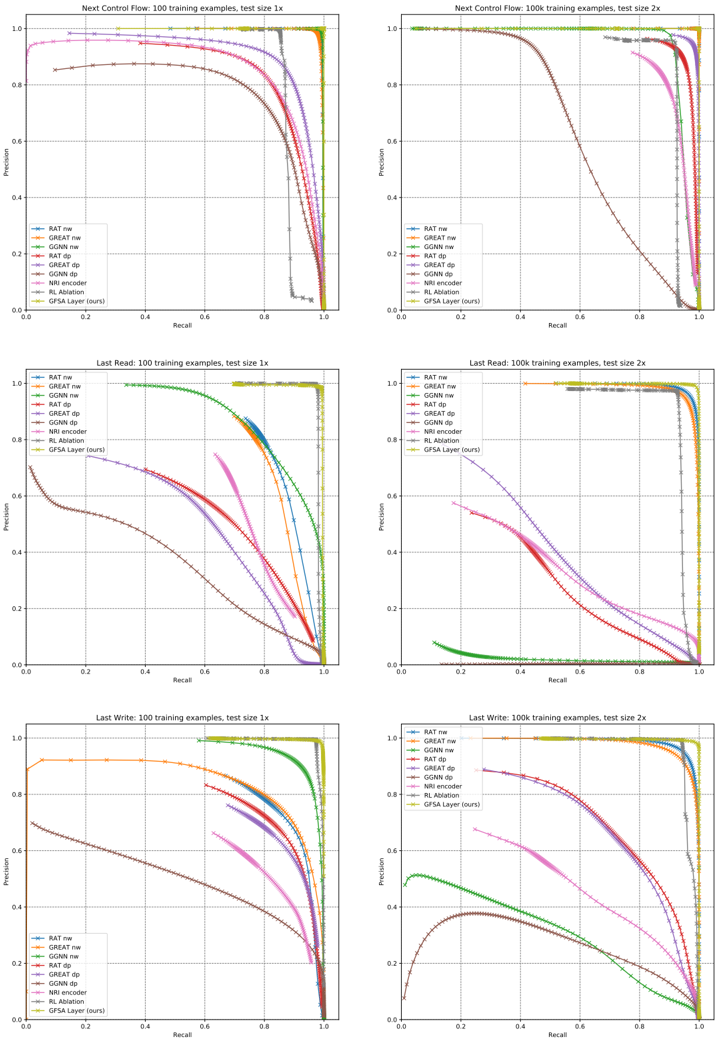
## Precision-Recall Curves for Different Models
### Overview
The image contains six precision-recall (PR) curves comparing the performance of various machine learning models across different tasks and configurations. Each graph represents a specific task (e.g., "Next Control Flow," "Last Read," "Last Write") with varying training example counts (100 or 100k) and test sizes (1x or 2x). The curves illustrate the trade-off between precision and recall for each model.
### Components/Axes
- **X-axis**: Recall (0.0 to 1.0)
- **Y-axis**: Precision (0.0 to 1.0)
- **Legends**:
- RAT nw (blue solid)
- GREAT nw (orange solid)
- GGNN nw (green solid)
- RAT dp (red dashed)
- GREAT dp (purple dashed)
- GGNN dp (brown dashed)
- NRI encoder (pink dash-dot)
- RL Ablation (gray dotted)
- GFSA Layer (ours) (yellow dotted)
- **Task Labels**:
- Top row: "Next Control Flow"
- Middle row: "Last Read"
- Bottom row: "Last Write"
- **Test Size**:
- Left column: 1x
- Right column: 2x
- **Training Examples**:
- 100 (top row)
- 100k (bottom row)
### Detailed Analysis
#### Next Control Flow (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.95 precision, drops sharply to ~0.8 at recall 0.2, then plateaus.
- **RAT nw**: Begins at ~0.9, declines gradually to ~0.7 at recall 0.8.
- **GREAT nw**: Starts at ~0.85, drops to ~0.6 at recall 0.6.
- **GGNN nw**: Declines slowly from ~0.8 to ~0.5 at recall 0.8.
- **RAT dp**: Sharp drop from ~0.9 to ~0.5 at recall 0.4.
- **GREAT dp**: Gradual decline from ~0.85 to ~0.4 at recall 0.7.
- **GGNN dp**: Starts at ~0.75, drops to ~0.3 at recall 0.6.
- **NRI encoder**: Flat at ~0.6 precision until recall 0.8, then drops.
- **RL Ablation**: Declines from ~0.7 to ~0.2 at recall 0.8.
#### Next Control Flow (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.95 precision until recall 0.3, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.6.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.5.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.7.
- **RAT dp**: Sharp drop from ~0.9 to ~0.5 at recall 0.4.
- **GREAT dp**: Gradual decline from ~0.85 to ~0.4 at recall 0.7.
- **GGNN dp**: Starts at ~0.75, drops to ~0.3 at recall 0.6.
- **NRI encoder**: Flat at ~0.6 precision until recall 0.8, then drops.
- **RL Ablation**: Declines from ~0.7 to ~0.2 at recall 0.8.
#### Last Read (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.9, drops to ~0.7 at recall 0.3, then plateaus.
- **RAT nw**: Begins at ~0.85, declines to ~0.6 at recall 0.5.
- **GREAT nw**: Starts at ~0.8, drops to ~0.5 at recall 0.4.
- **GGNN nw**: Declines from ~0.75 to ~0.4 at recall 0.6.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Read (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.9 precision until recall 0.2, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.4.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.3.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.5.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Write (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.9, drops to ~0.7 at recall 0.3, then plateaus.
- **RAT nw**: Begins at ~0.85, declines to ~0.6 at recall 0.5.
- **GREAT nw**: Starts at ~0.8, drops to ~0.5 at recall 0.4.
- **GGNN nw**: Declines from ~0.75 to ~0.4 at recall 0.6.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Write (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.9 precision until recall 0.2, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.4.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.3.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.5.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
### Key Observations
1. **GFSA Layer (ours)** consistently outperforms other models across all tasks and configurations, maintaining high precision even at high recall levels.
2. **Test size (1x vs 2x)** has minimal impact on model performance, with slight improvements in precision for most models at larger test sizes.
3. **Training example count (100 vs 100k)** significantly improves model performance, with higher precision and recall across all models.
4. **DP (data processing) models** (e.g., RAT dp, GREAT dp) generally underperform compared to their non-DP counterparts (e.g., RAT nw, GREAT nw).
5. **NRI encoder** shows flat precision-recall curves, indicating limited adaptability to varying recall levels.
6. **RL Ablation** (gray dotted line) consistently performs poorly, with steep declines in precision as recall increases.
### Interpretation
The data suggests that the **GFSA Layer (ours)** is the most robust model, maintaining high precision across varying recall levels and training conditions. The consistent performance of GFSA Layer across tasks and configurations indicates its generalizability. The underperformance of DP models (e.g., RAT dp, GREAT dp) suggests that data processing steps may introduce noise or reduce model effectiveness. The flat curves of the NRI encoder imply it struggles to adapt to different recall requirements, while RL Ablation's poor performance highlights the importance of reinforcement learning components in these tasks. The minimal impact of test size on performance suggests that model robustness is more influenced by training data quantity and architecture than test size.
DECODING INTELLIGENCE...