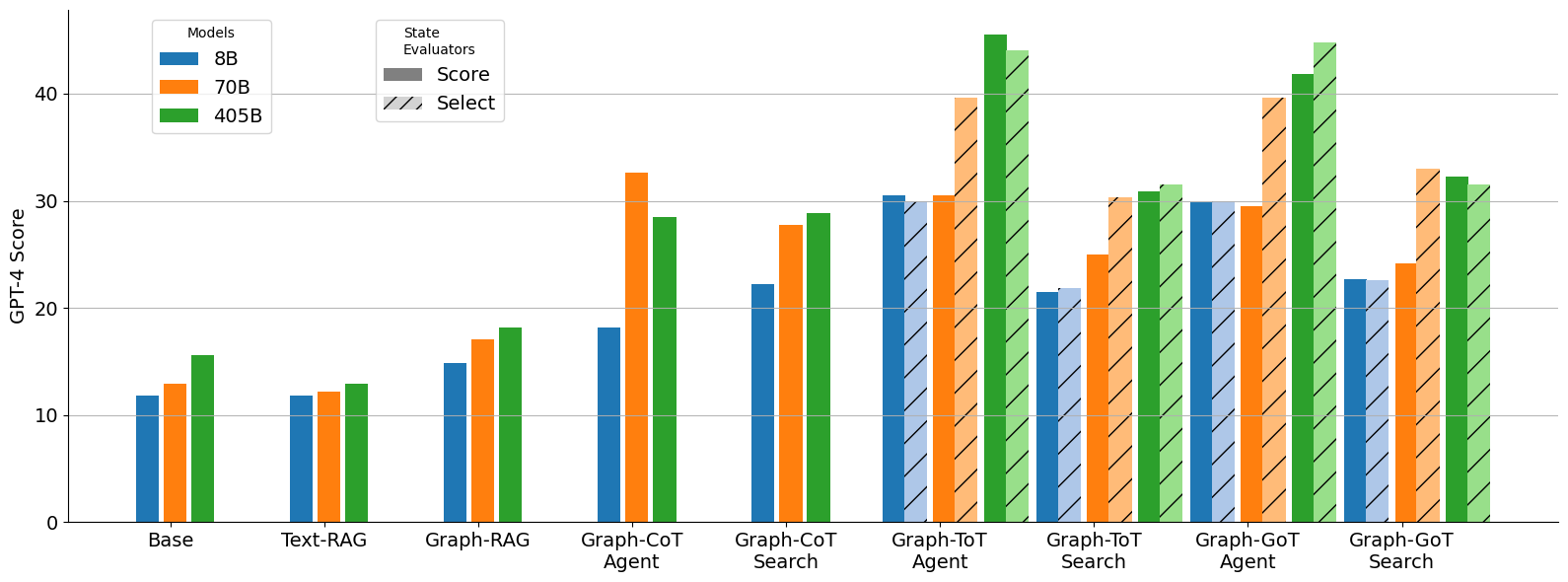
## Bar Chart: GPT-4 Score Comparison of Different Models and State Evaluators
### Overview
The image is a bar chart comparing the GPT-4 scores of different models (8B, 70B, 405B) across various state evaluators (Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, Graph-GoT Search). The chart also distinguishes between "Score" and "Select" state evaluators, with "Select" bars having a diagonal striped pattern.
### Components/Axes
* **Y-axis:** "GPT-4 Score", with a numerical scale from 0 to 40 in increments of 10.
* **X-axis:** Categorical axis representing different state evaluators: Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, Graph-GoT Search.
* **Legend (Models):** Located at the top-left of the chart.
* Blue: 8B model
* Orange: 70B model
* Green: 405B model
* **Legend (State Evaluators):** Located at the top-right of the chart.
* Gray: Score
* Diagonal Stripes: Select
### Detailed Analysis
Here's a breakdown of the GPT-4 scores for each model and state evaluator:
* **Base:**
* 8B: ~12
* 70B: ~13
* 405B: ~15
* **Text-RAG:**
* 8B: ~12
* 70B: ~13
* 405B: ~13
* **Graph-RAG:**
* 8B: ~15
* 70B: ~17
* 405B: ~18
* **Graph-CoT Agent:**
* 8B: ~18
* 70B: ~33
* 405B: ~29
* **Graph-CoT Search:**
* 8B: ~28
* 70B: ~29
* 405B: ~29
* **Graph-ToT Agent:**
* 8B (Select): ~31
* 70B (Select): ~31
* 405B (Select): ~45
* **Graph-ToT Search:**
* 8B: ~22
* 70B: ~30
* 405B: ~31
* **Graph-GoT Agent:**
* 8B: ~30
* 70B: ~30
* 405B: ~42
* **Graph-GoT Search:**
* 8B: ~24
* 70B: ~33
* 405B: ~32
### Key Observations
* The 405B model generally outperforms the 70B and 8B models across all state evaluators.
* The "Graph-ToT Agent" state evaluator with "Select" shows the highest score for the 405B model.
* The "Base" and "Text-RAG" state evaluators have the lowest scores across all models.
* The "Graph-CoT Search" state evaluator shows similar scores across all models.
* The "Graph-GoT Agent" and "Graph-GoT Search" state evaluators show high scores for the 405B model.
### Interpretation
The chart suggests that the choice of state evaluator significantly impacts the GPT-4 score, and that larger models (405B) tend to perform better. The "Graph-ToT Agent" state evaluator, particularly with the "Select" setting, appears to be the most effective for the 405B model. The relatively low scores for "Base" and "Text-RAG" indicate that these approaches may not be as effective as the graph-based methods. The similar scores for "Graph-CoT Search" across all models suggest that this approach may be less sensitive to model size.