TECHNICAL ASSET FINGERPRINT
d78bfc6cda286e0a8153ce9e
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
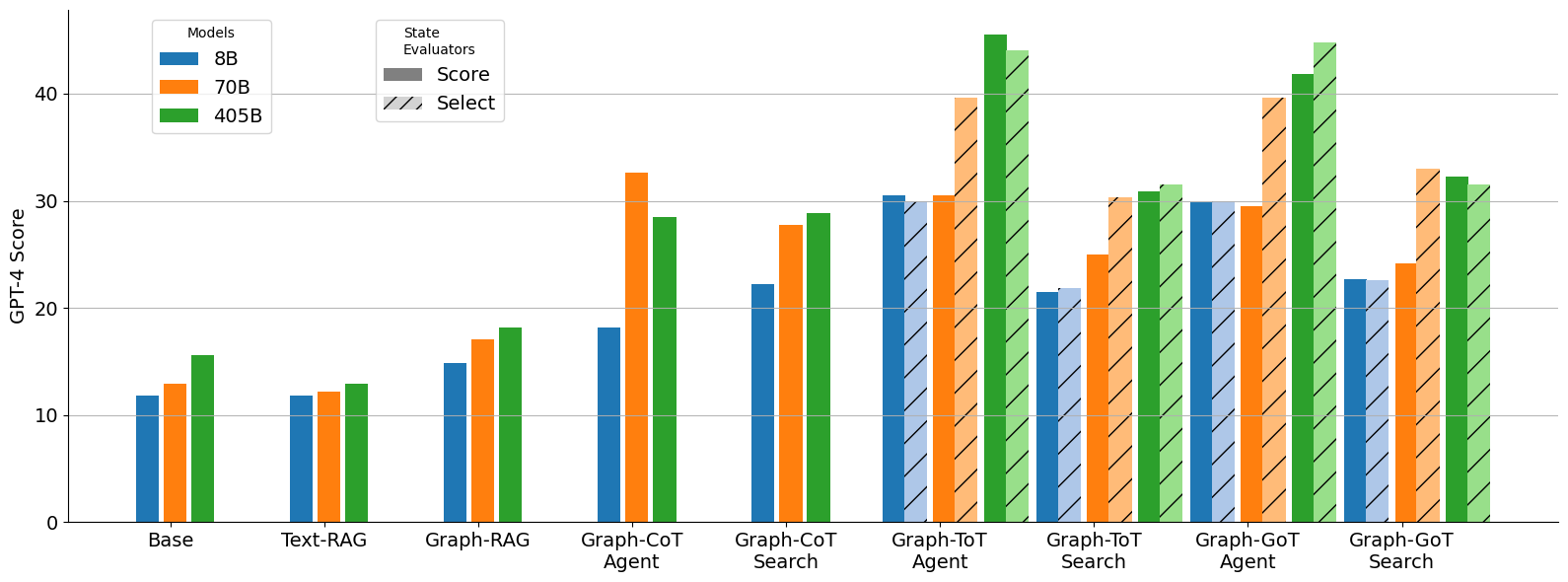
## Grouped Bar Chart: GPT-4 Scores by Model Size and Method
### Overview
This image is a grouped bar chart comparing the performance of different AI models (8B, 70B, 405B parameters) across various methods or techniques. The performance is measured by a "GPT-4 Score" on the y-axis. The chart evaluates two types of "State Evaluators": "Score" (solid bars) and "Select" (hatched bars).
### Components/Axes
* **Y-Axis:** Labeled "GPT-4 Score". The scale runs from 0 to 40, with major grid lines at intervals of 10.
* **X-Axis:** Lists nine distinct methods or experimental conditions. From left to right:
1. Base
2. Text-RAG
3. Graph-RAG
4. Graph-CoT Agent
5. Graph-CoT Search
6. Graph-ToT Agent
7. Graph-ToT Search
8. Graph-GoT Agent
9. Graph-GoT Search
* **Legend 1 (Top-Left):** "Models" with three color-coded categories:
* Blue: 8B
* Orange: 70B
* Green: 405B
* **Legend 2 (Top-Center):** "State Evaluators" with two pattern-coded categories:
* Solid fill: Score
* Diagonal hatching (///): Select
### Detailed Analysis
The chart presents data for each of the nine methods, with up to six bars per method (three model sizes, each with a "Score" and "Select" variant). Values are approximate based on visual alignment with the y-axis grid.
**1. Base**
* **8B (Blue):** Score ≈ 12. No Select bar.
* **70B (Orange):** Score ≈ 13. No Select bar.
* **405B (Green):** Score ≈ 16. No Select bar.
* *Trend:* Scores increase with model size.
**2. Text-RAG**
* **8B (Blue):** Score ≈ 12. No Select bar.
* **70B (Orange):** Score ≈ 12. No Select bar.
* **405B (Green):** Score ≈ 13. No Select bar.
* *Trend:* Minimal improvement over Base, with slight increase for 405B.
**3. Graph-RAG**
* **8B (Blue):** Score ≈ 15. No Select bar.
* **70B (Orange):** Score ≈ 17. No Select bar.
* **405B (Green):** Score ≈ 18. No Select bar.
* *Trend:* Clear improvement over Text-RAG for all model sizes.
**4. Graph-CoT Agent**
* **8B (Blue):** Score ≈ 18. No Select bar.
* **70B (Orange):** Score ≈ 33. No Select bar.
* **405B (Green):** Score ≈ 29. No Select bar.
* *Trend:* Significant jump for 70B and 405B models. The 70B model outperforms the 405B model here.
**5. Graph-CoT Search**
* **8B (Blue):** Score ≈ 22. No Select bar.
* **70B (Orange):** Score ≈ 28. No Select bar.
* **405B (Green):** Score ≈ 29. No Select bar.
* *Trend:* Consistent improvement with model size. Scores are generally higher than Graph-CoT Agent for 8B and 405B.
**6. Graph-ToT Agent**
* **8B (Blue):** Score ≈ 31, Select ≈ 30.
* **70B (Orange):** Score ≈ 30, Select ≈ 40.
* **405B (Green):** Score ≈ 46, Select ≈ 44.
* *Trend:* Highest scores observed so far. The 405B model achieves the chart's peak score (≈46). For 70B, the "Select" evaluator yields a much higher score than the "Score" evaluator.
**7. Graph-ToT Search**
* **8B (Blue):** Score ≈ 21, Select ≈ 22.
* **70B (Orange):** Score ≈ 25, Select ≈ 31.
* **405B (Green):** Score ≈ 31, Select ≈ 32.
* *Trend:* Scores are lower than the "Agent" variant for the same method. The "Select" evaluator consistently scores slightly higher than the "Score" evaluator.
**8. Graph-GoT Agent**
* **8B (Blue):** Score ≈ 30, Select ≈ 30.
* **70B (Orange):** Score ≈ 30, Select ≈ 40.
* **405B (Green):** Score ≈ 42, Select ≈ 45.
* *Trend:* Very high performance, comparable to Graph-ToT Agent. The 405B "Select" bar (≈45) is among the highest on the chart. The 70B model again shows a large gap between "Score" and "Select".
**9. Graph-GoT Search**
* **8B (Blue):** Score ≈ 23, Select ≈ 22.
* **70B (Orange):** Score ≈ 24, Select ≈ 33.
* **405B (Green):** Score ≈ 32, Select ≈ 31.
* *Trend:* Similar pattern to Graph-ToT Search: "Agent" variants outperform "Search" variants. The 70B "Select" score is notably higher than its "Score".
### Key Observations
1. **Method Superiority:** The "Graph-ToT Agent" and "Graph-GoT Agent" methods achieve the highest overall scores, particularly for the 405B model.
2. **Model Size Impact:** Larger models (405B) generally perform better, but this is not absolute. The 70B model outperforms the 405B in the "Graph-CoT Agent" condition.
3. **Agent vs. Search:** For both ToT (Tree-of-Thought) and GoT (Graph-of-Thought) methods, the "Agent" variant consistently yields higher scores than the "Search" variant.
4. **Evaluator Discrepancy:** For the high-performing Agent methods (ToT and GoT), the "Select" evaluator (hatched bars) often produces a significantly higher score than the standard "Score" evaluator, especially for the 70B model.
5. **Baseline Progression:** There is a clear progression in performance from Base → Text-RAG → Graph-RAG, establishing a baseline improvement from simple to graph-based retrieval.
### Interpretation
This chart demonstrates the efficacy of advanced reasoning frameworks (CoT, ToT, GoT) when applied to graph-based structures, especially in an "Agent" configuration. The data suggests that:
* **Structured Reasoning Matters:** Moving from simple retrieval (Text-RAG) to graph retrieval (Graph-RAG) and then to structured reasoning over those graphs (CoT/ToT/GoT Agents) yields substantial performance gains.
* **The "Agent" Paradigm is Key:** The significant drop from "Agent" to "Search" variants for ToT and GoT implies that the agentic loop—where the model actively plans, executes, and self-corrects—is crucial for maximizing performance on this GPT-4 evaluation metric.
* **Evaluation Method Influences Results:** The discrepancy between "Score" and "Select" evaluators, particularly for the 70B model in Agent modes, indicates that the evaluation protocol itself can dramatically affect the reported outcome. "Select" may represent a more favorable or lenient evaluation criterion.
* **Scale Isn't Everything:** The anomaly where 70B outperforms 405B in "Graph-CoT Agent" suggests that for certain method-model combinations, factors beyond raw parameter count (like training data or alignment for that specific task) play a critical role. The overall trend, however, still favors scale, as seen in the peak performance of the 405B model in the most advanced methods.
In summary, the chart argues for the development of AI systems that combine large-scale models with sophisticated, graph-aware agentic reasoning frameworks, while also highlighting the importance of the evaluation methodology in assessing their true capability.
DECODING INTELLIGENCE...