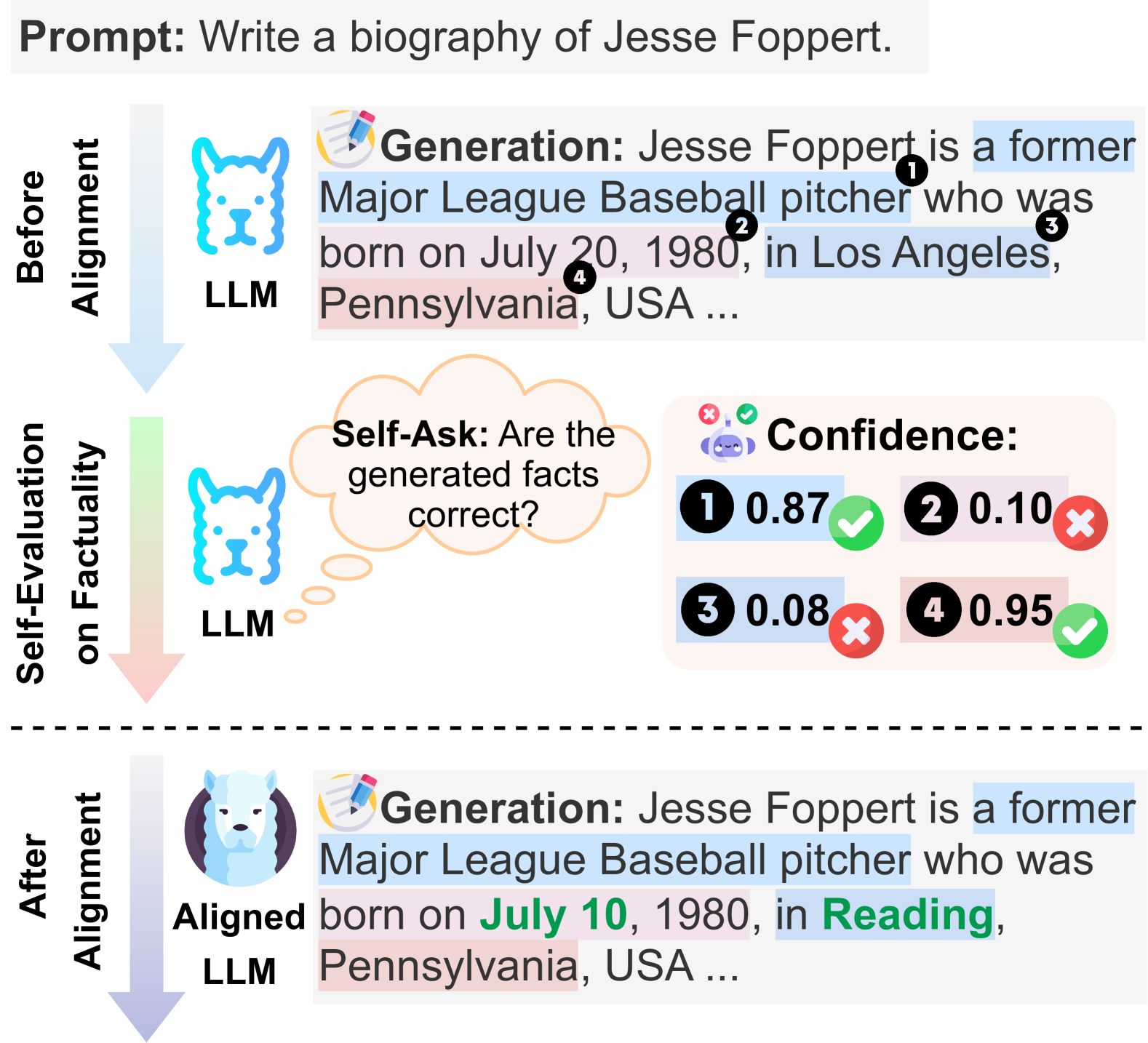
## Diagram: LLM Factuality Alignment Process
### Overview
This diagram illustrates a three-stage process for improving the factual accuracy of a Large Language Model's (LLM) generated text. It compares the model's output "Before Alignment" with its output "After Alignment," highlighting a self-evaluation step that assesses confidence in generated facts. The process uses a specific example: generating a biography of baseball player Jesse Foppert.
### Components/Axes
The diagram is structured vertically into three distinct sections, separated by horizontal lines and connected by downward-pointing arrows indicating process flow.
1. **Top Section: "Before Alignment"**
* **Left Label:** "Before Alignment" (vertical text).
* **Icon:** A blue, stylized dog head labeled "LLM".
* **Content Block:** A text generation box with a pencil icon and the header "Generation:".
* **Generated Text:** "Jesse Foppert is a former Major League Baseball pitcher who was born on July 20, 1980, in Los Angeles, Pennsylvania, USA ..."
* **Annotations:** Four numbered black circles (1, 2, 3, 4) are placed over specific parts of the text, linking them to confidence scores in the next section.
2. **Middle Section: "Self-Evaluation on Factuality"**
* **Left Label:** "Self-Evaluation on Factuality" (vertical text).
* **Icon:** The same blue dog head icon labeled "LLM".
* **Thought Bubble:** Contains the text "Self-Ask: Are the generated facts correct?".
* **Confidence Panel:** A box titled "Confidence:" with a robot icon. It contains four entries, each with a number, a decimal score, and a symbol:
* 1: 0.87 (Green checkmark)
* 2: 0.10 (Red X)
* 3: 0.08 (Red X)
* 4: 0.95 (Green checkmark)
3. **Bottom Section: "After Alignment"**
* **Left Label:** "After Alignment" (vertical text).
* **Icon:** A new, more detailed icon of a white llama/alpaca head labeled "Aligned LLM".
* **Content Block:** A text generation box identical in style to the first.
* **Generated Text:** "Jesse Foppert is a former Major League Baseball pitcher who was born on **July 10**, 1980, in **Reading**, Pennsylvania, USA ..."
* **Annotations:** The text "July 10" and "Reading" are highlighted in green, indicating corrected information.
### Detailed Analysis
* **Prompt:** The initial input is "Prompt: Write a biography of Jesse Foppert."
* **Initial Generation (Before Alignment):** The LLM produces a biographical sentence. Four specific factual claims are tagged:
1. "a former Major League Baseball pitcher"
2. "July 20, 1980" (birth date)
3. "Los Angeles" (birth city)
4. "Pennsylvania, USA" (birth state/country)
* **Self-Evaluation:** The model internally queries the correctness of its generated facts. The confidence scores suggest:
* High confidence (0.87) in claim #1 (profession).
* Very low confidence (0.10) in claim #2 (birth date).
* Very low confidence (0.08) in claim #3 (birth city).
* High confidence (0.95) in claim #4 (birth state/country).
* **Aligned Generation:** After the alignment process, the LLM produces a revised sentence. The elements with low confidence scores (#2 and #3) have been corrected:
* Birth date changed from "July 20" to "**July 10**".
* Birth city changed from "Los Angeles" to "**Reading**".
* The high-confidence elements (#1 and #4) remain unchanged.
### Key Observations
1. **Process Flow:** The diagram clearly depicts a linear workflow: Generation -> Self-Evaluation -> Corrected Generation.
2. **Visual Coding:** Color and icons are used systematically. Blue represents the base LLM, white/llama represents the aligned model. Green highlights and checkmarks indicate correct/high-confidence information, while red X's indicate errors/low confidence.
3. **Targeted Correction:** The alignment process does not regenerate the entire text from scratch. It specifically identifies and corrects only the low-confidence segments, preserving the high-confidence parts.
4. **Confidence as a Signal:** The numerical confidence scores (0.10, 0.08) directly correlate with the factual errors in the initial output, demonstrating their utility as a diagnostic tool.
### Interpretation
This diagram demonstrates a method for **mitigating hallucinations and improving factual reliability in LLMs** through a process of internal self-evaluation and targeted correction. The core idea is that an LLM can be trained or prompted to assess its own confidence in discrete pieces of generated information.
* **What it suggests:** The "Aligned LLM" is not necessarily more knowledgeable at its base, but is better at **recognizing the limits of its own knowledge**. It uses a confidence metric to flag uncertain claims, which can then be verified or corrected, possibly via an external knowledge retrieval step (not shown) or through refined decoding strategies.
* **How elements relate:** The "Self-Evaluation" stage is the critical innovation. It acts as a filter between raw generation and final output. The confidence scores are the key output of this stage, directly determining which parts of the text are subject to revision in the "After Alignment" phase.
* **Notable pattern:** The model exhibits high confidence in general, common-sense facts (a player's profession, their state of birth) but low confidence in specific, precise details (exact date, city). This aligns with known characteristics of LLM knowledge distributions.
* **Underlying mechanism:** The shift from a "dog" to a "llama" icon symbolizes a change in the model's architecture or training paradigm (e.g., from a base model to one fine-tuned with reinforcement learning from human feedback (RLHF) or a similar alignment technique that incorporates factuality rewards). The process shown is a conceptual representation of how such alignment can manifest in practice.