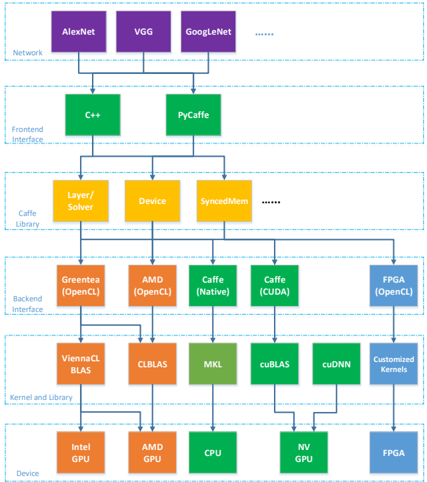
## Layered Architecture Diagram: Caffe Deep Learning Framework Stack
### Overview
This image is a technical architecture diagram illustrating the layered software stack of the Caffe deep learning framework. It shows how high-level neural network models connect through various interface and library layers down to specific hardware devices. The diagram is organized into six horizontal layers, with components represented as colored boxes and dependencies shown via downward-pointing arrows.
### Components/Axes (Layer Structure)
The diagram is segmented into six distinct horizontal layers, each labeled on the left side. From top to bottom:
1. **Network** (Top Layer)
* **Components**: Three purple boxes labeled `AlexNet`, `VGG`, `GoogleNet`, followed by an ellipsis (`......`).
* **Positioning**: These are the highest-level components, representing pre-defined neural network architectures.
2. **Frontend Interface**
* **Components**: Two green boxes labeled `C++` and `PyCaffe`.
* **Flow**: Arrows from the `Network` layer point to both of these boxes, indicating these are the primary interfaces for defining and using networks.
3. **Caffe Library**
* **Components**: Three yellow boxes labeled `Layer/Solver`, `Device`, `SyncedMem`, followed by an ellipsis (`......`).
* **Flow**: Arrows from both `C++` and `PyCaffe` converge and point to this layer, showing it is the core library accessed by the frontends.
4. **Backend Interface**
* **Components**: Five boxes in varying colors:
* Orange: `Greenes (OpenCL)`
* Orange: `AMD (OpenCL)`
* Green: `Caffe (Native)`
* Green: `Caffe (CUDA)`
* Blue: `FPGA (OpenCL)`
* **Flow**: Arrows from the `Caffe Library` layer point to each of these boxes, indicating multiple backend implementations are supported.
5. **Kernel and Library**
* **Components**: Six boxes:
* Orange: `ViennaCL BLAS`
* Orange: `CLBLAS`
* Green: `MKL`
* Green: `cuBLAS`
* Green: `cuDNN`
* Blue: `Customized Kernels`
* **Flow**: Arrows from the `Backend Interface` layer connect to specific boxes here. For example, `Greenes (OpenCL)` and `AMD (OpenCL)` connect to `ViennaCL BLAS` and `CLBLAS`. `Caffe (CUDA)` connects to `cuBLAS` and `cuDNN`.
6. **Device** (Bottom Layer)
* **Components**: Five boxes:
* Orange: `Intel GPU`
* Orange: `AMD GPU`
* Green: `CPU`
* Green: `NV GPU`
* Blue: `FPGA`
* **Flow**: Arrows from the `Kernel and Library` layer point to the corresponding hardware devices. `ViennaCL BLAS`/`CLBLAS` point to `Intel GPU` and `AMD GPU`. `MKL` points to `CPU`. `cuBLAS`/`cuDNN` point to `NV GPU`. `Customized Kernels` points to `FPGA`.
### Detailed Analysis
* **Color Coding**: The diagram uses color to group related components across layers.
* **Purple**: High-level network models.
* **Green**: Primary/native Caffe components (Frontend, Native/CUDA Backends, CPU-focused libraries/devices).
* **Yellow**: Core Caffe library modules.
* **Orange**: OpenCL-based components for AMD and Intel GPUs.
* **Blue**: FPGA-specific components.
* **Dependency Flow**: The arrows create a clear top-down dependency chain: `Network` -> `Frontend` -> `Core Library` -> `Backend` -> `Kernel/Library` -> `Hardware Device`.
* **Ellipses**: The `......` in the `Network` and `Caffe Library` layers explicitly indicate that the list of networks and library modules is not exhaustive; more exist beyond those shown.
### Key Observations
1. **Multi-Backend Support**: The architecture is explicitly designed to support multiple computational backends (Native, CUDA, OpenCL for different vendors, FPGA) from a single core library.
2. **Hardware Abstraction**: The stack provides a clear abstraction from high-level network definitions down to heterogeneous hardware (CPUs, GPUs from different vendors, FPGAs).
3. **Vendor-Specific Optimization Paths**: The diagram shows dedicated optimization paths for different hardware, such as using NVIDIA's `cuDNN` for `NV GPU` and vendor-specific OpenCL libraries for `AMD GPU` and `Intel GPU`.
4. **Modularity**: Each layer has a distinct responsibility, allowing for components (like a new backend or kernel library) to be potentially swapped or added.
### Interpretation
This diagram is a blueprint for a portable and extensible deep learning deployment system. It demonstrates how the Caffe framework achieves hardware portability not by being generic, but by having specialized, optimized pathways for different hardware targets.
The **key insight** is the separation between the *algorithmic definition* (Network, Frontend, Core Library) and the *computational execution* (Backend, Kernel, Device). This allows researchers to define a model once (e.g., in `PyCaffe`) and have it run on a wide array of hardware, from a standard `CPU` to a high-end `NV GPU` or an embedded `FPGA`, by selecting the appropriate backend path.
The presence of both `Caffe (Native)` and `Caffe (CUDA)` backends suggests a fallback mechanism: native code for CPU execution and CUDA for NVIDIA GPU acceleration. The inclusion of OpenCL backends for AMD and Intel GPUs, along with a dedicated FPGA path, highlights an intentional design goal of vendor and hardware agnosticism, which is critical for deployment in diverse operational environments (e.g., data centers vs. edge devices). The ellipses indicate this is a scalable architecture meant to incorporate future networks and libraries.