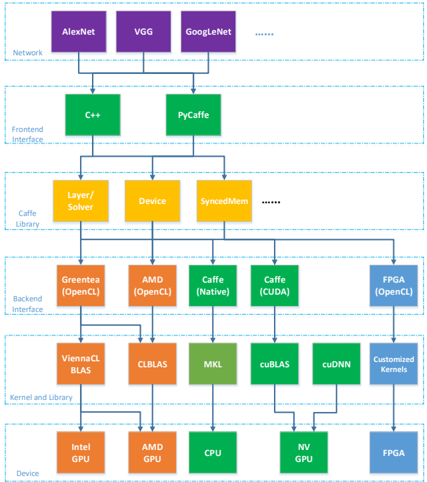
## System Architecture Diagram: Deep Learning Framework Stack
### Overview
The diagram illustrates a multi-layered technical architecture for a deep learning system, organized hierarchically from high-level frameworks to hardware devices. Components are color-coded and connected via arrows indicating dependencies or data flow.
### Components/Axes
- **Legend**:
- Purple: Network Layer
- Green: Frontend Interface
- Yellow: Middleware
- Orange: Backend Interface
- Blue: Device Layer
- **Structure**:
- Top-to-bottom hierarchy with bidirectional arrows between layers
- Left-to-right grouping of related components
### Detailed Analysis
1. **Network Layer (Purple)**
- Contains deep learning frameworks: AlexNet, VGG, GoogleNet
- Positioned at the top, suggesting foundational role
2. **Frontend Interface (Green)**
- Programming languages/tools: C++, PyCaffe
- Directly connected to Middleware layer
3. **Middleware (Yellow)**
- Core components: Layer/Solver, Device, SyncMem
- Acts as intermediary between Frontend and Backend
4. **Backend Interface (Orange)**
- Hardware acceleration frameworks:
- OpenCL (Green), OpenCL (Orange)
- Caffe (Native), Caffe (CUDA)
- Positioned above Device layer
5. **Device Layer (Blue)**
- Hardware components:
- Intel GPU, AMD GPU, CPU, NV GPU, FPGA
- Bottom layer with direct connections to Backend Interface
### Key Observations
- **Hierarchical Dependency**:
- Network → Frontend → Middleware → Backend → Devices
- Arrows show data flow from frameworks to hardware
- **Color Consistency**:
- All OpenCL components share orange color despite different hardware targets
- Caffe appears in both Native and CUDA variants (green/blue)
- **Hardware Diversity**:
- Device layer includes both GPU architectures (Intel/AMD/NV) and FPGA
- **Middleware Role**:
- SyncMem component suggests synchronization mechanisms between layers
### Interpretation
This architecture demonstrates a vertically integrated deep learning stack optimized for performance:
1. **Framework Specialization**:
- Top layer focuses on pre-trained models (AlexNet/VGG/GoogleNet)
- Middleware handles computational graph operations (Layer/Solver)
2. **Hardware Optimization**:
- Backend Interface shows framework-specific hardware acceleration (CUDA/OpenCL)
- Device layer supports heterogeneous computing (GPUs + FPGA)
3. **Interoperability**:
- Cross-layer connections (e.g., C++ → OpenCL) enable framework-hardware integration
- SyncMem component implies coordination between parallel processing units
The diagram suggests a system designed for maximum computational efficiency, with clear separation between software frameworks and hardware acceleration while maintaining interoperability through standardized interfaces (OpenCL, CUDA). The inclusion of FPGA alongside GPUs indicates flexibility for different acceleration needs.