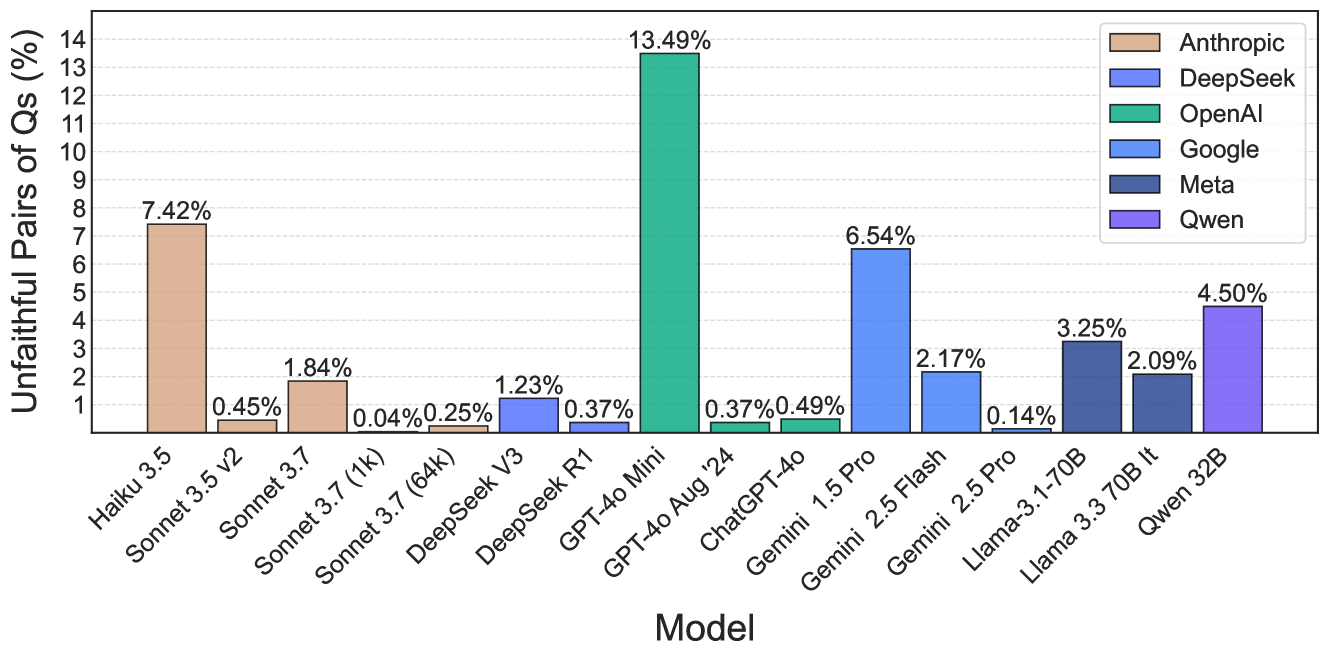
## Bar Chart: Unfaithful Pairs of Qs (%) Across AI Models
### Overview
The chart compares the percentage of "Unfaithful Pairs of Qs" across various AI models, with bars colored by model family (Anthropic, DeepSeek, OpenAI, Google, Meta, Qwen). The y-axis ranges from 0% to 14%, and the x-axis lists specific model versions.
### Components/Axes
- **X-axis (Models)**:
- Haiku 3.5, Sonnet 3.5 v2, Sonnet 3.7 (1k), Sonnet 3.7 (64k), DeepSeek V3, DeepSeek R1, GPT-4o Mini, GPT-4o Aug '24, ChatGPT-4o, Gemini 1.5 Pro, Gemini 2.5 Flash, Gemini 2.5 Pro, Llama-3 70B It, Llama-3 3.3 70B It, Qwen 32B.
- **Y-axis (Unfaithful Pairs of Qs %)**: 0% to 14% in increments of 1%.
- **Legend**:
- Anthropic (brown), DeepSeek (blue), OpenAI (green), Google (light blue), Meta (dark blue), Qwen (purple).
### Detailed Analysis
- **Anthropic Models**:
- Haiku 3.5: 7.42% (brown).
- Sonnet 3.5 v2: 0.45% (brown).
- Sonnet 3.7 (1k): 1.84% (brown).
- Sonnet 3.7 (64k): 0.04% (brown).
- **DeepSeek Models**:
- DeepSeek V3: 1.23% (blue).
- DeepSeek R1: 0.37% (blue).
- **OpenAI Models**:
- GPT-4o Mini: 13.49% (green).
- GPT-4o Aug '24: 0.37% (green).
- ChatGPT-4o: 0.49% (green).
- **Google Models**:
- Gemini 1.5 Pro: 6.54% (light blue).
- Gemini 2.5 Flash: 2.17% (light blue).
- Gemini 2.5 Pro: 0.14% (light blue).
- **Meta Models**:
- Llama-3 70B It: 3.25% (dark blue).
- Llama-3 3.3 70B It: 2.09% (dark blue).
- **Qwen Models**:
- Qwen 32B: 4.50% (purple).
### Key Observations
1. **Highest Unfaithful Pairs**: GPT-4o Mini (OpenAI) dominates at 13.49%, far exceeding other models.
2. **Lowest Unfaithful Pairs**: Sonnet 3.7 (64k) (Anthropic) at 0.04% and Gemini 2.5 Pro (Google) at 0.14%.
3. **Model Family Trends**:
- OpenAI models show extreme variability (GPT-4o Mini: 13.49% vs. GPT-4o Aug '24: 0.37%).
- Google models cluster between 0.14% and 6.54%.
- Anthropic models range from 0.04% to 7.42%.
4. **Notable Outliers**:
- GPT-4o Mini’s 13.49% is an extreme outlier compared to all other models.
- Qwen 32B (4.50%) and Llama-3 70B It (3.25%) are the second-highest performers.
### Interpretation
The data suggests significant variability in "Unfaithful Pairs of Qs" across AI models, with OpenAI’s GPT-4o Mini exhibiting the highest rate. This could reflect differences in training data, architectural choices, or evaluation methodologies. Google and Anthropic models generally show lower rates, though Gemini 1.5 Pro (6.54%) and Haiku 3.5 (7.42%) are notable exceptions. The disparity between GPT-4o Mini and other models raises questions about potential overfitting, evaluation criteria, or dataset-specific behaviors. Further investigation into the definition of "unfaithful pairs" and its operationalization across models would clarify these trends.