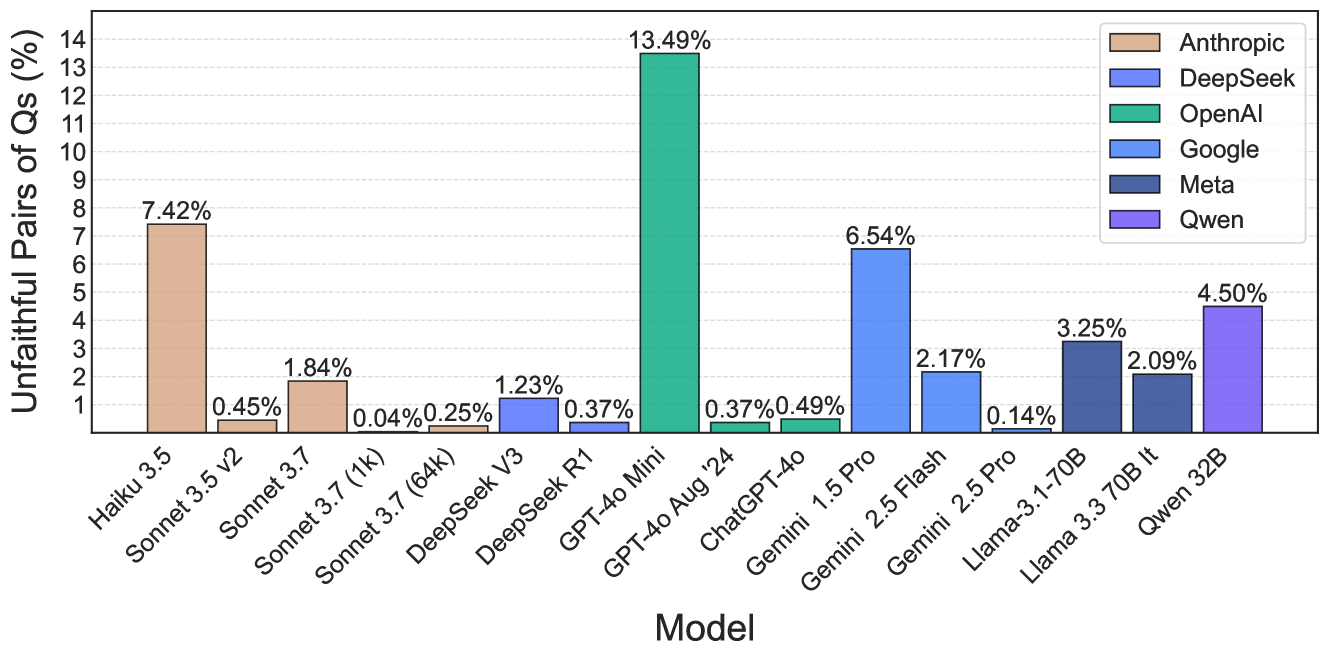
## Bar Chart: Unfaithful Pairs of Qs (%) by Model
### Overview
The image is a bar chart comparing the percentage of unfaithful pairs of questions (Qs) across various language models. The x-axis represents the model names, and the y-axis represents the percentage of unfaithful pairs of questions. The chart includes a legend that maps each model provider (Anthropic, DeepSeek, OpenAI, Google, Meta, Qwen) to a specific color.
### Components/Axes
* **Y-axis:** "Unfaithful Pairs of Qs (%)" with a scale from 0 to 14, incrementing by 1.
* **X-axis:** "Model" with the following models listed:
* Haiku 3.5
* Sonnet 3.5 v2
* Sonnet 3.7
* Sonnet 3.7 (1k)
* Sonnet 3.7 (64k)
* DeepSeek V3
* DeepSeek R1
* GPT-4o Mini
* GPT-4o Aug '24
* ChatGPT-4o
* Gemini 1.5 Pro
* Gemini 2.5 Flash
* Gemini 2.5 Pro
* Llama-3.1-70B
* Llama 3.3 70B It
* Qwen 32B
* **Legend (Top-Right):**
* Anthropic (Tan)
* DeepSeek (Blue)
* OpenAI (Teal)
* Google (Light Blue)
* Meta (Dark Blue)
* Qwen (Lavender)
### Detailed Analysis
Here's a breakdown of the percentage of unfaithful pairs of questions for each model, grouped by provider:
* **Anthropic (Tan):**
* Haiku 3.5: 7.42%
* Sonnet 3.5 v2: 0.45%
* Sonnet 3.7: 1.84%
* Sonnet 3.7 (1k): 0.04%
* Sonnet 3.7 (64k): 0.25%
* **DeepSeek (Blue):**
* DeepSeek V3: 1.23%
* DeepSeek R1: 0.37%
* **OpenAI (Teal):**
* GPT-4o Mini: 13.49%
* GPT-4o Aug '24: 0.37%
* **Google (Light Blue):**
* ChatGPT-4o: 0.49%
* Gemini 1.5 Pro: 6.54%
* Gemini 2.5 Flash: 2.17%
* Gemini 2.5 Pro: 0.14%
* **Meta (Dark Blue):**
* Llama-3.1-70B: 3.25%
* Llama 3.3 70B It: 2.09%
* **Qwen (Lavender):**
* Qwen 32B: 4.50%
### Key Observations
* GPT-4o Mini (OpenAI) has the highest percentage of unfaithful pairs of questions at 13.49%.
* Haiku 3.5 (Anthropic) has the second-highest percentage at 7.42%.
* Several models, including Sonnet 3.7 (1k), Gemini 2.5 Pro, have very low percentages (close to 0%).
### Interpretation
The bar chart provides a comparison of the "faithfulness" of different language models, as measured by the percentage of unfaithful question pairs. A lower percentage indicates better faithfulness.
* **Model Performance:** OpenAI's GPT-4o Mini exhibits a significantly higher rate of unfaithful question pairs compared to other models, suggesting potential issues with its reliability or consistency in generating responses. Anthropic's Haiku 3.5 also shows a relatively high percentage.
* **Provider Comparison:** There is considerable variation in faithfulness across models from different providers. For example, Google's Gemini models show a range of faithfulness, with Gemini 1.5 Pro having a higher percentage than Gemini 2.5 Pro.
* **Model Size/Version Impact:** Within the Anthropic models, the Sonnet 3.7 series shows varying faithfulness depending on the version (1k, 64k), indicating that model size or specific training configurations can influence faithfulness.
* **Potential Implications:** The data suggests that certain models may be more prone to generating inconsistent or unreliable responses, which could have implications for their use in applications where accuracy and consistency are critical.