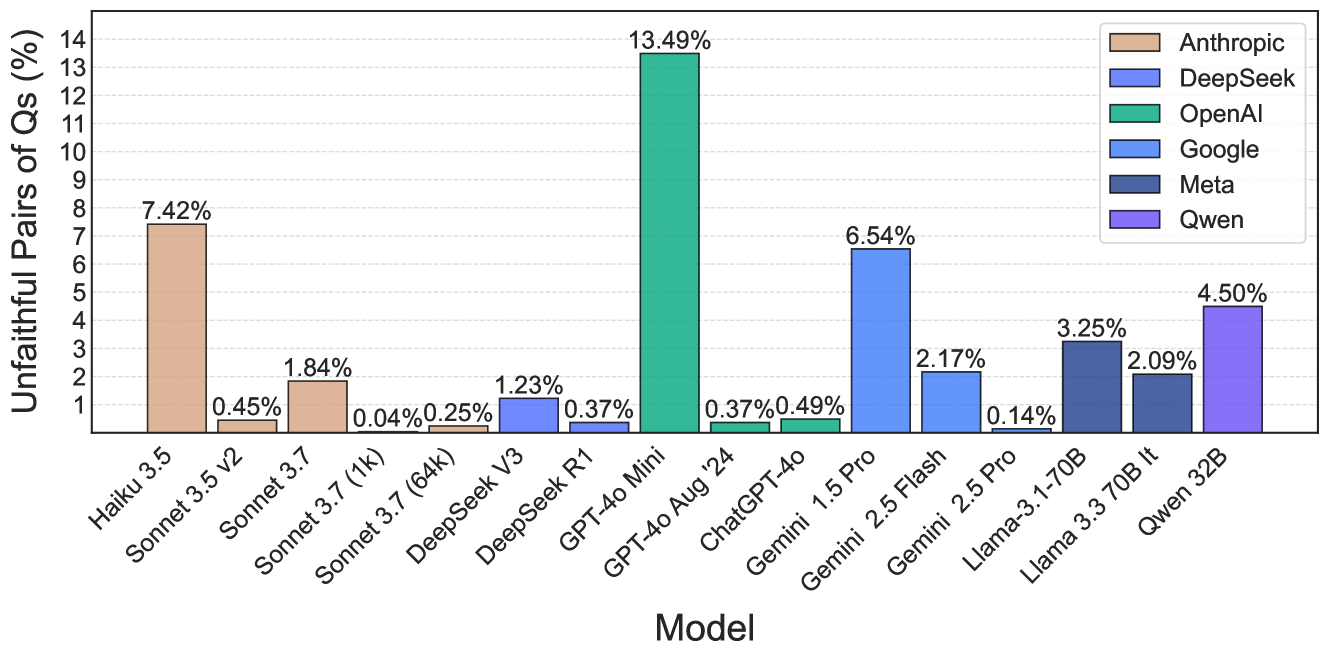
## Bar Chart: Unfaithful Pairs of Questions (%) by Model
### Overview
This bar chart compares the percentage of "unfaithful pairs of questions" (Qs) across various language models. The x-axis represents the model name, and the y-axis represents the percentage of unfaithful pairs, ranging from 0% to 14%. Each model is represented by a different colored bar.
### Components/Axes
* **X-axis Title:** Model
* **Y-axis Title:** Unfaithful Pairs of Qs (%)
* **Y-axis Scale:** Linear, from 0 to 14, with increments of 1.
* **Legend:** Located in the top-right corner.
* Anthropic (Red)
* DeepSeek (Dark Blue)
* OpenAI (Green)
* Google (Blue)
* Meta (Light Blue)
* Qwen (Gray)
* **Models (X-axis labels):**
* Haiku 3.5
* Sonnet 3.5 v2
* Sonnet 3.7
* Sonnet 3.7 (1k)
* DeepSeek V3
* DeepSeek R1
* GPT-4o Mini
* GPT-4o Aug '24
* ChatGPT-4o
* Gemini 1.5 Pro
* Gemini 2.5 Flash
* Llama-3 1-70B
* Llama 3 3.70B It
* Qwen 32B
### Detailed Analysis
Here's a breakdown of the data, model by model, with approximate values based on visual inspection:
* **Haiku 3.5 (Red):** 7.42%
* **Sonnet 3.5 v2 (Red):** 0.45%
* **Sonnet 3.7 (Red):** 1.84%
* **Sonnet 3.7 (1k) (Red):** 0.04%
* **DeepSeek V3 (Dark Blue):** 0.25%
* **DeepSeek R1 (Dark Blue):** 1.23%
* **GPT-4o Mini (Green):** 0.37%
* **GPT-4o Aug '24 (Green):** 13.49%
* **ChatGPT-4o (Blue):** 0.37%
* **Gemini 1.5 Pro (Blue):** 6.54%
* **Gemini 2.5 Flash (Blue):** 0.49%
* **Llama-3 1-70B (Light Blue):** 2.17%
* **Llama 3 3.70B It (Light Blue):** 0.14%
* **Qwen 32B (Gray):** 4.50%
**Trends:**
* The Anthropic models (Haiku 3.5, Sonnet series) show a wide range of values.
* GPT-4o Aug '24 has the highest percentage of unfaithful pairs, significantly higher than other models.
* DeepSeek models generally have low percentages.
* Gemini models show a mix of low and moderate percentages.
* Meta's Llama models have moderate percentages.
* Qwen 32B has a moderate percentage.
### Key Observations
* GPT-4o Aug '24 is a clear outlier with a very high percentage (13.49%).
* Sonnet 3.7 (1k) has a very low percentage (0.04%).
* The range of percentages is quite large, indicating significant differences in the "faithfulness" of these models.
### Interpretation
The chart demonstrates the varying levels of "unfaithfulness" across different language models when dealing with pairs of questions. "Unfaithfulness" likely refers to inconsistencies or errors in responses when presented with related questions. The significant outlier, GPT-4o Aug '24, suggests a potential issue with this specific version of the model, possibly related to its training data or architecture. The wide range of values across the Anthropic models indicates that different model sizes or training approaches within the same family can lead to substantial differences in performance. The relatively low percentages for DeepSeek models suggest they may be more consistent in their responses. This data is valuable for developers and users of these models, as it highlights potential areas for improvement and informs decisions about which model to use for specific applications. The chart suggests that model choice should be carefully considered based on the desired level of consistency and reliability.