## Line Chart: The training dynamics of simple prompt guidance
### Overview
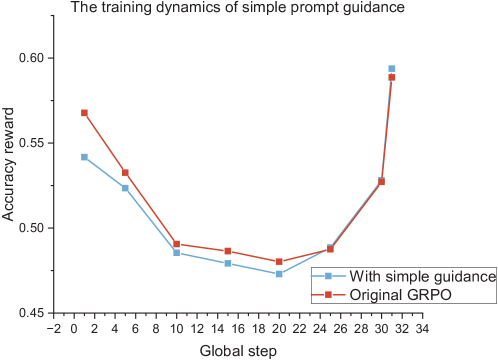
The image is a line chart comparing the accuracy reward of two methods, "With simple guidance" and "Original GRPO," over global steps. The chart shows how the accuracy reward changes as the global step increases for both methods.
### Components/Axes
* **Title:** The training dynamics of simple prompt guidance
* **X-axis:** Global step, with markers at -2, 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, and 34.
* **Y-axis:** Accuracy reward, with markers at 0.45, 0.50, 0.55, and 0.60.
* **Legend:** Located in the bottom-right corner.
* Blue line with square markers: "With simple guidance"
* Red line with square markers: "Original GRPO"
### Detailed Analysis
* **"With simple guidance" (Blue Line):**
* Trend: Initially decreases, reaches a minimum, and then increases.
* Data Points:
* (-2, 0.54 ± 0.01)
* (4, 0.52 ± 0.01)
* (10, 0.49 ± 0.01)
* (16, 0.48 ± 0.01)
* (22, 0.47 ± 0.01)
* (26, 0.49 ± 0.01)
* (32, 0.59 ± 0.01)
* **"Original GRPO" (Red Line):**
* Trend: Initially decreases, reaches a minimum, and then increases sharply.
* Data Points:
* (0, 0.57 ± 0.01)
* (6, 0.53 ± 0.01)
* (12, 0.49 ± 0.01)
* (18, 0.48 ± 0.01)
* (24, 0.49 ± 0.01)
* (30, 0.52 ± 0.01)
* (32, 0.59 ± 0.01)
### Key Observations
* Both methods show a similar trend: a decrease in accuracy reward followed by an increase.
* The "Original GRPO" method starts with a higher accuracy reward but experiences a more significant drop initially.
* Towards the end of the global steps, the "Original GRPO" method shows a sharper increase in accuracy reward compared to "With simple guidance."
* The minimum accuracy reward for both methods occurs around global steps 18-22.
### Interpretation
The chart suggests that both "With simple guidance" and "Original GRPO" methods have a similar dynamic during training. Initially, the accuracy reward decreases, possibly indicating a period of exploration or adjustment. However, as the training progresses (higher global steps), both methods show an improvement in accuracy reward. The "Original GRPO" method, despite starting higher, experiences a more pronounced initial drop but ultimately exhibits a more rapid recovery and increase in accuracy reward towards the end of the training period. This could indicate that "Original GRPO" is more sensitive to initial conditions but potentially more effective in the long run. The similar trend suggests that both methods are influenced by the same underlying factors during training, but the magnitude of the impact differs.