## Diagram: Neural Network Architecture Comparison
### Overview
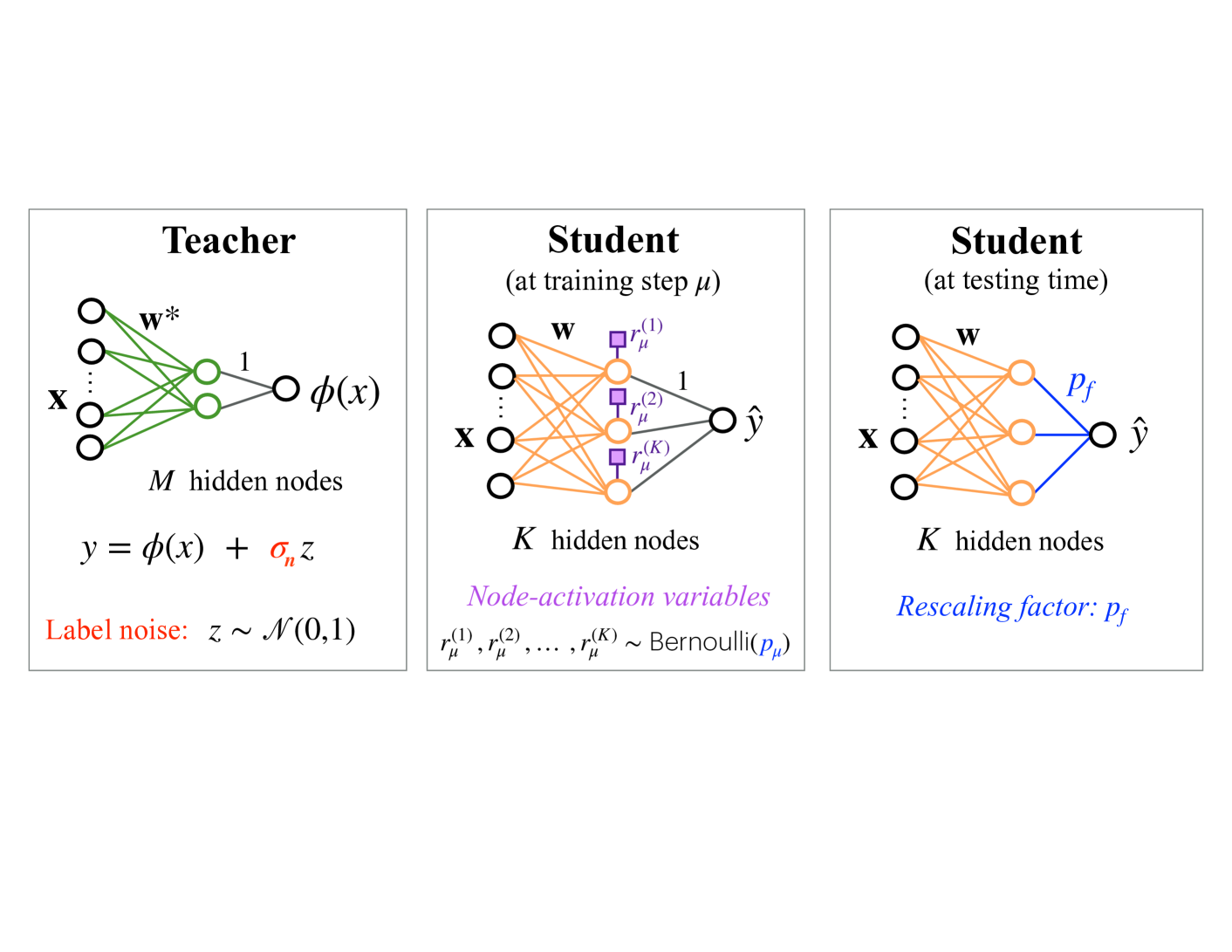
The image compares three neural network architectures: a **Teacher** model and two **Student** models (one at training step μ and one at testing time). Each diagram includes hidden layers, activation functions, and noise/rescaling mechanisms.
### Components/Axes
1. **Teacher Model**
- **Input**: `x` (features)
- **Hidden Layer**: `M` nodes (green connections)
- **Output**: `y = φ(x) + σₙz`
- `φ(x)`: Nonlinear function
- `σₙz`: Label noise (`z ~ N(0,1)`)
- **Color Coding**: Green edges for hidden nodes.
2. **Student Model (Training Step μ)**
- **Input**: `x`
- **Hidden Layer**: `K` nodes (orange connections)
- **Node-Activation Variables**: `r_μ^(1), r_μ^(2), ..., r_μ^(K)` (purple blocks)
- **Output**: `ŷ` (predicted label)
- **Color Coding**: Orange edges for hidden nodes; purple blocks for activation variables.
3. **Student Model (Testing Time)**
- **Input**: `x`
- **Hidden Layer**: `K` nodes (orange connections)
- **Rescaling Factor**: `p_f` (blue edge to output)
- **Output**: `ŷ` (predicted label)
- **Color Coding**: Orange edges for hidden nodes; blue edge for rescaling.
### Detailed Analysis
- **Teacher Model**:
- Output includes label noise (`z ~ N(0,1)`), simulating real-world data imperfections.
- Uses `M` hidden nodes with green connections.
- **Student Model (Training)**:
- Introduces `K` hidden nodes (orange) and node-activation variables (`r_μ^(i)`) to adjust learning dynamics.
- Activation variables are Bernoulli-distributed (`r_μ^(i) ~ Bernoulli(p_μ)`), acting as stochastic gates.
- **Student Model (Testing)**:
- Applies a **rescaling factor** (`p_f`) to the output, likely to adapt predictions to the Teacher’s noisy outputs.
- Maintains `K` hidden nodes but removes activation variables during testing.
### Key Observations
1. **Noise vs. Rescaling**:
- The Teacher introduces label noise (`z`), while the testing Student uses `p_f` to rescale outputs, suggesting a refinement step.
2. **Architectural Simplification**:
- Students reduce hidden nodes from `M` (Teacher) to `K` (Students), indicating knowledge distillation.
3. **Training vs. Testing**:
- Training Student uses activation variables (`r_μ^(i)`), which are absent in the testing phase, implying they are only used during learning.
### Interpretation
This diagram illustrates a **knowledge distillation framework** where:
- The **Teacher** model generates noisy outputs (`y = φ(x) + σₙz`) to simulate real-world uncertainty.
- The **Student** models learn from the Teacher during training by adjusting node activations (`r_μ^(i)`) and later apply a rescaling factor (`p_f`) to refine predictions during testing.
- The reduction in hidden nodes (`M → K`) and removal of activation variables in testing suggest the Student distills the Teacher’s knowledge into a simpler, more efficient model.
- The use of Bernoulli-distributed activation variables (`r_μ^(i)`) introduces stochasticity during training, potentially improving generalization.
The framework emphasizes robustness to label noise and efficient knowledge transfer from a complex Teacher to a streamlined Student.