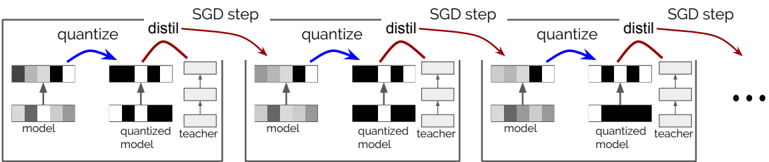
## Diagram: Iterative Quantization and Distillation Process in Machine Learning
### Overview
The diagram illustrates a multi-step iterative process for optimizing machine learning models through quantization and distillation. It depicts three sequential "SGD step" blocks, each containing a "quantize" operation followed by a "distil" operation. The flow progresses from an initial model through repeated cycles of quantization and distillation, with each step producing a refined "quantized model" and "teacher model."
### Components/Axes
1. **Key Elements**:
- **Model**: Initial unquantized model (represented by gray/black bars).
- **Quantized Model**: Output of the "quantize" step (black/white bars).
- **Teacher Model**: Output of the "distil" step (stacked rectangles).
- **Arrows**:
- **Blue**: "quantize" operation (model → quantized model).
- **Red**: "distil" operation (quantized model → teacher model).
- **Labels**:
- "quantize" (blue arrows).
- "distil" (red arrows).
- "SGD step" (horizontal gray lines separating iterations).
- "model," "quantized model," "teacher" (text annotations).
2. **Structure**:
- Three identical "SGD step" blocks arranged horizontally.
- Each block contains:
- Top: "quantize" → "distil" flow.
- Bottom: "model" → "quantized model" → "teacher" hierarchy.
- Final ellipsis (...) indicates continuation of the process beyond the third step.
### Detailed Analysis
- **Quantization Process**:
- Converts the original model's parameters (gray/black bars) into a simplified, binary representation (black/white bars).
- Reduces computational complexity and memory footprint.
- **Distillation Process**:
- Transfers knowledge from the quantized model to a "teacher model" (stacked rectangles).
- Likely improves generalization or accuracy while maintaining quantization benefits.
- **Iterative Workflow**:
- Each "SGD step" refines the model further:
1. **Step 1**: Initial model → quantized model → teacher model.
2. **Step 2**: Updated model → quantized model → refined teacher model.
3. **Step 3**: Further refined model → quantized model → advanced teacher model.
- The teacher model grows in complexity (stacked rectangles) with each iteration.
### Key Observations
1. **Color-Coded Flow**:
- Blue arrows (quantize) precede red arrows (distil) in every step.
- No feedback loops or cross-step dependencies are shown.
2. **Model Complexity**:
- The teacher model's stacked rectangles suggest increasing depth or parameterization after each distillation.
3. **Repetition**:
- The ellipsis (...) implies the process is designed for indefinite iteration, common in training pipelines.
### Interpretation
This diagram represents a **knowledge distillation pipeline** optimized for efficiency. By alternating quantization (model compression) and distillation (knowledge transfer), the process balances:
- **Efficiency**: Reduced computational demands via quantization.
- **Accuracy**: Improved generalization via distillation from the quantized model.
The iterative SGD steps suggest this is part of a larger training loop, where each cycle refines the model's balance between size and performance. The teacher model's growing complexity implies that distillation acts as a regularization mechanism, preventing over-simplification from repeated quantization. This approach is particularly relevant in edge computing or resource-constrained environments where model size and speed are critical.