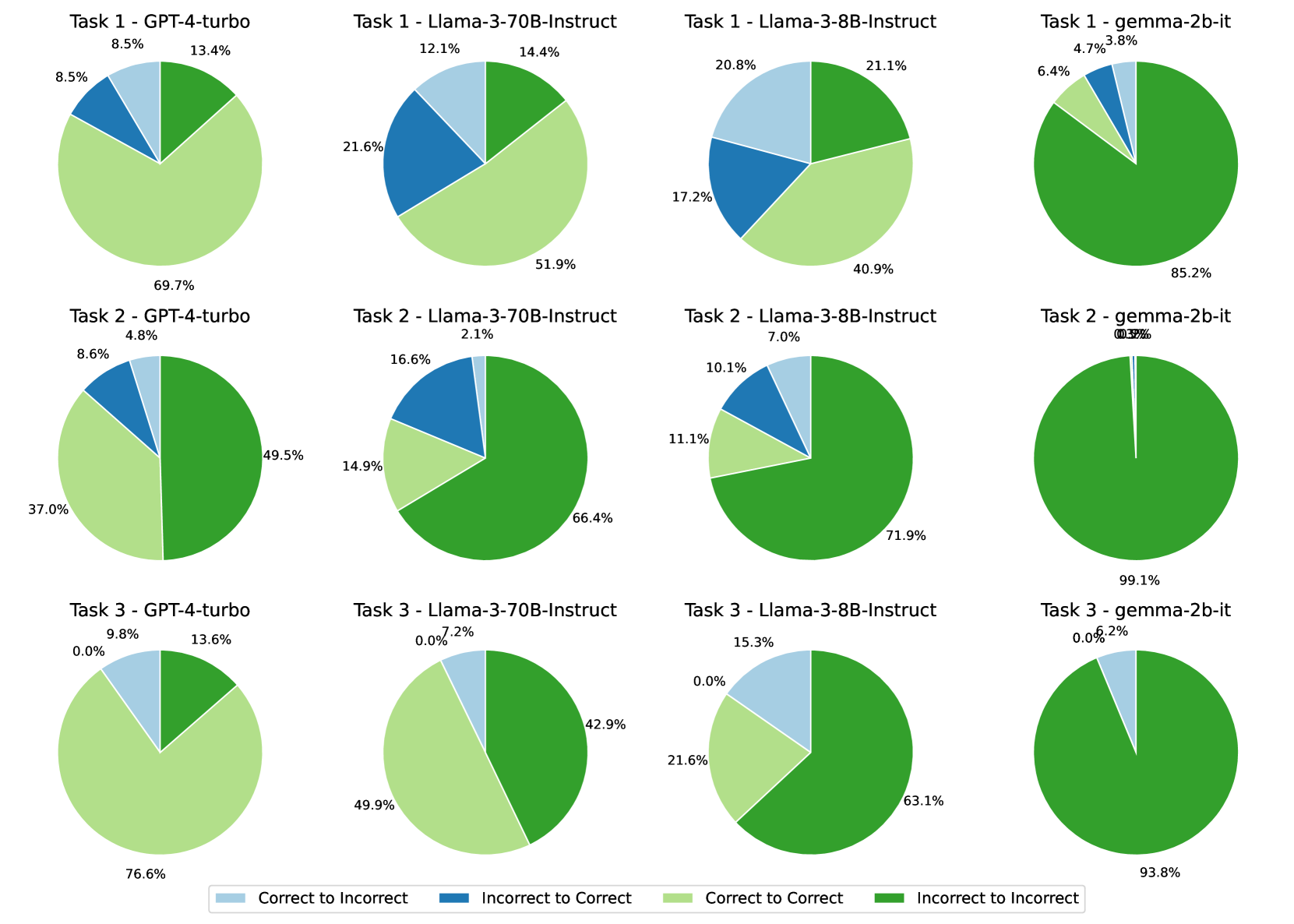
## Pie Chart Grid: Model Performance on Tasks
### Overview
The image presents a grid of pie charts comparing the performance of different language models (GPT-4-turbo, Llama-3-70B-Instruct, Llama-3-8B-Instruct, and gemma-2b-it) across three tasks. Each pie chart visualizes the percentage of responses that fall into one of four categories: "Correct to Incorrect", "Incorrect to Correct", "Correct to Correct", and "Incorrect to Incorrect".
### Components/Axes
* **Grid Structure:** The pie charts are arranged in a 3x4 grid. Each row represents a task (Task 1, Task 2, Task 3), and each column represents a different language model.
* **Pie Chart Segments:** Each pie chart is divided into four segments, each representing a different category of response transition.
* **Labels:** Each pie chart has a title indicating the task number and the model name (e.g., "Task 1 - GPT-4-turbo").
* **Percentages:** Each segment of the pie chart is labeled with a percentage value.
* **Legend:** Located at the bottom of the image, the legend maps colors to response categories:
* Light Blue: "Correct to Incorrect"
* Dark Blue: "Incorrect to Correct"
* Light Green: "Correct to Correct"
* Dark Green: "Incorrect to Incorrect"
### Detailed Analysis
**Task 1**
* **GPT-4-turbo:**
* Correct to Incorrect: 8.5%
* Incorrect to Correct: 8.5%
* Correct to Correct: 69.7%
* Incorrect to Incorrect: 13.4%
* **Llama-3-70B-Instruct:**
* Correct to Incorrect: 12.1%
* Incorrect to Correct: 21.6%
* Correct to Correct: 51.9%
* Incorrect to Incorrect: 14.4%
* **Llama-3-8B-Instruct:**
* Correct to Incorrect: 20.8%
* Incorrect to Correct: 17.2%
* Correct to Correct: 40.9%
* Incorrect to Incorrect: 21.1%
* **gemma-2b-it:**
* Correct to Incorrect: 3.8%
* Incorrect to Correct: 6.4%
* Correct to Correct: 4.7%
* Incorrect to Incorrect: 85.2%
**Task 2**
* **GPT-4-turbo:**
* Correct to Incorrect: 4.8%
* Incorrect to Correct: 8.6%
* Correct to Correct: 37.0%
* Incorrect to Incorrect: 49.5%
* **Llama-3-70B-Instruct:**
* Correct to Incorrect: 2.1%
* Incorrect to Correct: 16.6%
* Correct to Correct: 14.9%
* Incorrect to Incorrect: 66.4%
* **Llama-3-8B-Instruct:**
* Correct to Incorrect: 7.0%
* Incorrect to Correct: 10.1%
* Correct to Correct: 11.1%
* Incorrect to Incorrect: 71.9%
* **gemma-2b-it:**
* Correct to Incorrect: 0.3%
* Incorrect to Correct: 0.3% (estimated, value is unreadable)
* Correct to Correct: 0.3% (estimated, value is unreadable)
* Incorrect to Incorrect: 99.1%
**Task 3**
* **GPT-4-turbo:**
* Correct to Incorrect: 9.8%
* Incorrect to Correct: 0.0%
* Correct to Correct: 76.6%
* Incorrect to Incorrect: 13.6%
* **Llama-3-70B-Instruct:**
* Correct to Incorrect: 7.2%
* Incorrect to Correct: 0.0%
* Correct to Correct: 49.9%
* Incorrect to Incorrect: 42.9%
* **Llama-3-8B-Instruct:**
* Correct to Incorrect: 15.3%
* Incorrect to Correct: 0.0%
* Correct to Correct: 21.6%
* Incorrect to Incorrect: 63.1%
* **gemma-2b-it:**
* Correct to Incorrect: 0.2%
* Incorrect to Correct: 0.0%
* Correct to Correct: 6.2% (estimated, value is unreadable)
* Incorrect to Incorrect: 93.8%
### Key Observations
* **GPT-4-turbo** generally has the highest percentage of "Correct to Correct" responses across all three tasks, except for Task 2 where it is outperformed by the other models.
* **gemma-2b-it** consistently shows a very high percentage of "Incorrect to Incorrect" responses, indicating it struggles with these tasks.
* **Llama-3-70B-Instruct** and **Llama-3-8B-Instruct** show varying performance depending on the task, with a tendency towards higher "Incorrect to Incorrect" percentages compared to GPT-4-turbo.
* For Task 3, all models have 0.0% "Incorrect to Correct" responses.
### Interpretation
The pie charts provide a visual comparison of the performance of different language models on a set of tasks. The "Correct to Correct" percentage can be interpreted as a measure of the model's accuracy and consistency. The "Incorrect to Incorrect" percentage indicates the model's tendency to consistently fail on certain inputs. The "Correct to Incorrect" and "Incorrect to Correct" percentages may reflect the model's ability to learn or adapt during the task.
The data suggests that GPT-4-turbo generally outperforms the other models in terms of accuracy and consistency. gemma-2b-it appears to struggle significantly with these tasks. The Llama models show intermediate performance, with some variability depending on the specific task.
The fact that all models have 0% "Incorrect to Correct" responses for Task 3 could indicate that this task is particularly challenging or that the models are not designed to correct their mistakes in this specific context.