\n
## Pie Charts: Model Performance on Tasks 1-3
### Overview
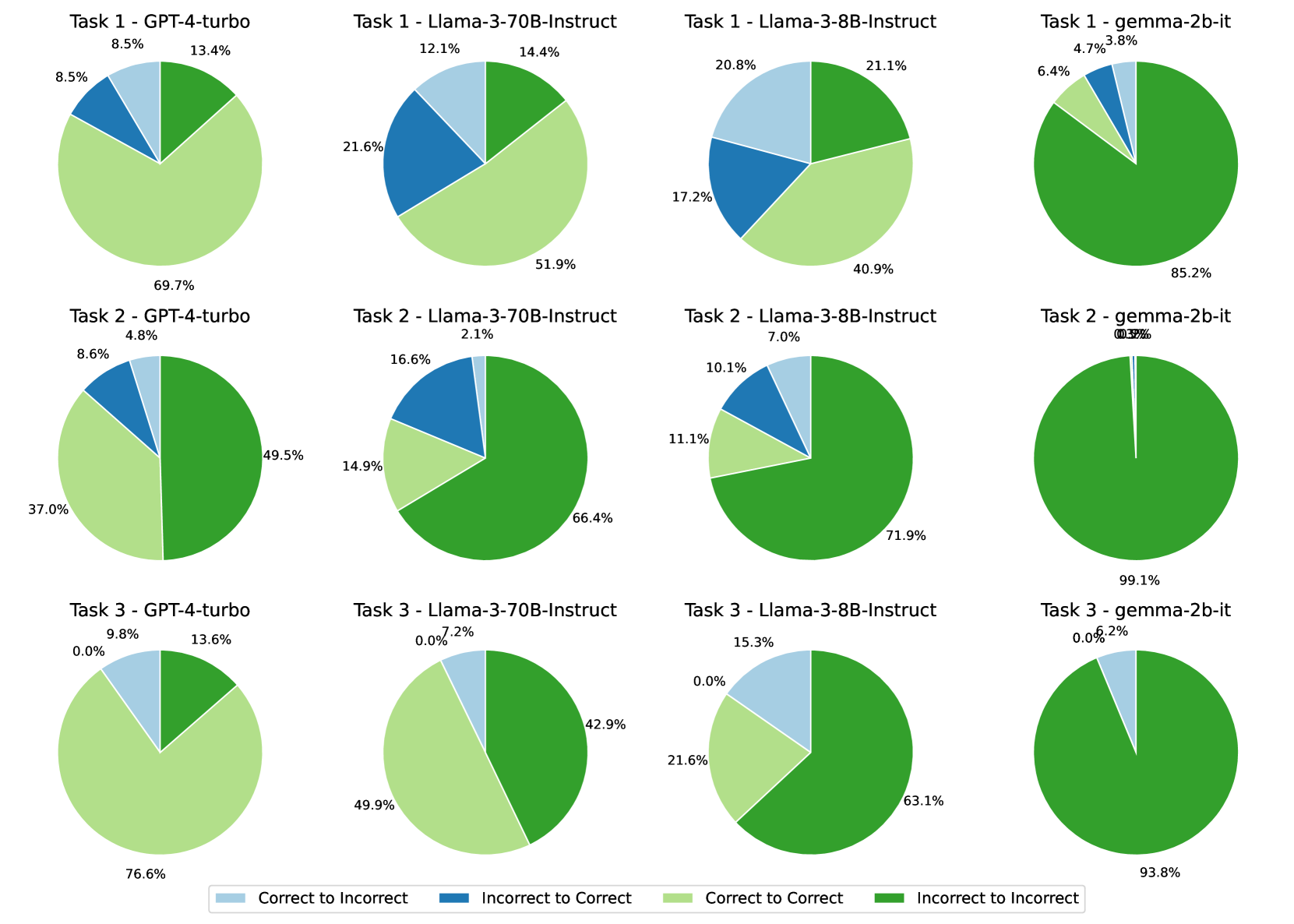
The image presents a 3x4 grid of pie charts, visualizing the performance of four different language models (GPT-4-turbo, Llama-3-70B-Instruct, Llama-3-8B-Instruct, and Gemma-2b-it) across three tasks. Each pie chart represents the distribution of "Correct to Incorrect" and "Incorrect to Correct" classifications for a specific model-task combination.
### Components/Axes
The charts are pie charts, with each slice representing a proportion of the total. The legend at the bottom of the image defines the colors used:
* **Correct to Incorrect:** Light Green
* **Incorrect to Correct:** Blue
* **Correct to Correct:** Yellow
* **Incorrect to Incorrect:** Dark Green
Each chart is labeled with "Task [Number] - [Model Name]". The percentages displayed within each slice represent the proportion of each category.
### Detailed Analysis or Content Details
**Task 1:**
* **GPT-4-turbo:** Approximately 8.5% Correct to Incorrect, 13.4% Incorrect to Correct, 21.6% Correct to Correct, 56.5% Incorrect to Incorrect.
* **Llama-3-70B-Instruct:** Approximately 12.1% Correct to Incorrect, 14.4% Incorrect to Correct, 51.9% Correct to Correct, 21.6% Incorrect to Incorrect.
* **Llama-3-8B-Instruct:** Approximately 20.8% Correct to Incorrect, 21.1% Incorrect to Correct, 40.9% Correct to Correct, 17.2% Incorrect to Incorrect.
* **Gemma-2b-it:** Approximately 6.4% Correct to Incorrect, 3.8% Incorrect to Correct, 85.2% Correct to Correct, 4.7% Incorrect to Incorrect.
**Task 2:**
* **GPT-4-turbo:** Approximately 4.8% Correct to Incorrect, 8.6% Incorrect to Correct, 37.0% Correct to Correct, 69.7% Incorrect to Incorrect.
* **Llama-3-70B-Instruct:** Approximately 2.1% Correct to Incorrect, 16.6% Incorrect to Correct, 66.4% Correct to Correct, 14.9% Incorrect to Incorrect.
* **Llama-3-8B-Instruct:** Approximately 7.0% Correct to Incorrect, 10.1% Incorrect to Correct, 71.9% Correct to Correct, 11.1% Incorrect to Incorrect.
* **Gemma-2b-it:** Approximately 0.3% Correct to Incorrect, 0.5% Incorrect to Correct, 98.2% Correct to Correct, 1.0% Incorrect to Incorrect.
**Task 3:**
* **GPT-4-turbo:** Approximately 0.0% Correct to Incorrect, 9.8% Incorrect to Correct, 13.6% Correct to Correct, 76.6% Incorrect to Incorrect.
* **Llama-3-70B-Instruct:** Approximately 0.0% Correct to Incorrect, 7.2% Incorrect to Correct, 49.9% Correct to Correct, 42.9% Incorrect to Incorrect.
* **Llama-3-8B-Instruct:** Approximately 15.3% Correct to Incorrect, 21.6% Incorrect to Correct, 63.1% Correct to Correct.
* **Gemma-2b-it:** Approximately 0.0% Correct to Incorrect, 2.0% Incorrect to Correct, 99.1% Correct to Correct, 0.0% Incorrect to Incorrect.
### Key Observations
* Gemma-2b-it consistently demonstrates the highest proportion of "Correct to Correct" classifications across all three tasks, often exceeding 85%.
* GPT-4-turbo consistently shows the highest proportion of "Incorrect to Incorrect" classifications, particularly in Task 3, where it reaches 76.6%.
* Llama-3-70B-Instruct and Llama-3-8B-Instruct generally exhibit a more balanced distribution between "Correct to Correct" and "Incorrect to Incorrect" compared to GPT-4-turbo and Gemma-2b-it.
* The "Correct to Incorrect" and "Incorrect to Correct" categories generally represent smaller proportions of the total for all models and tasks.
### Interpretation
The data suggests that Gemma-2b-it is the most reliable model in terms of consistently classifying correctly, minimizing errors. GPT-4-turbo, while potentially capable, appears to have a higher tendency to make incorrect classifications, as evidenced by the large proportion of "Incorrect to Incorrect" results. The Llama models fall in between, demonstrating a more balanced performance.
The "Correct to Incorrect" and "Incorrect to Correct" categories likely represent instances where the model misclassifies the direction of the correction (e.g., identifying a correction as an error, or vice versa). The dominance of "Correct to Correct" for Gemma-2b-it indicates a strong ability to accurately assess the validity of corrections. The high "Incorrect to Incorrect" for GPT-4-turbo suggests it may be more prone to making errors and failing to recognize valid corrections.
The differences in performance across tasks could be due to the inherent difficulty of each task or the specific types of errors being evaluated. Further investigation would be needed to determine the underlying reasons for these variations.