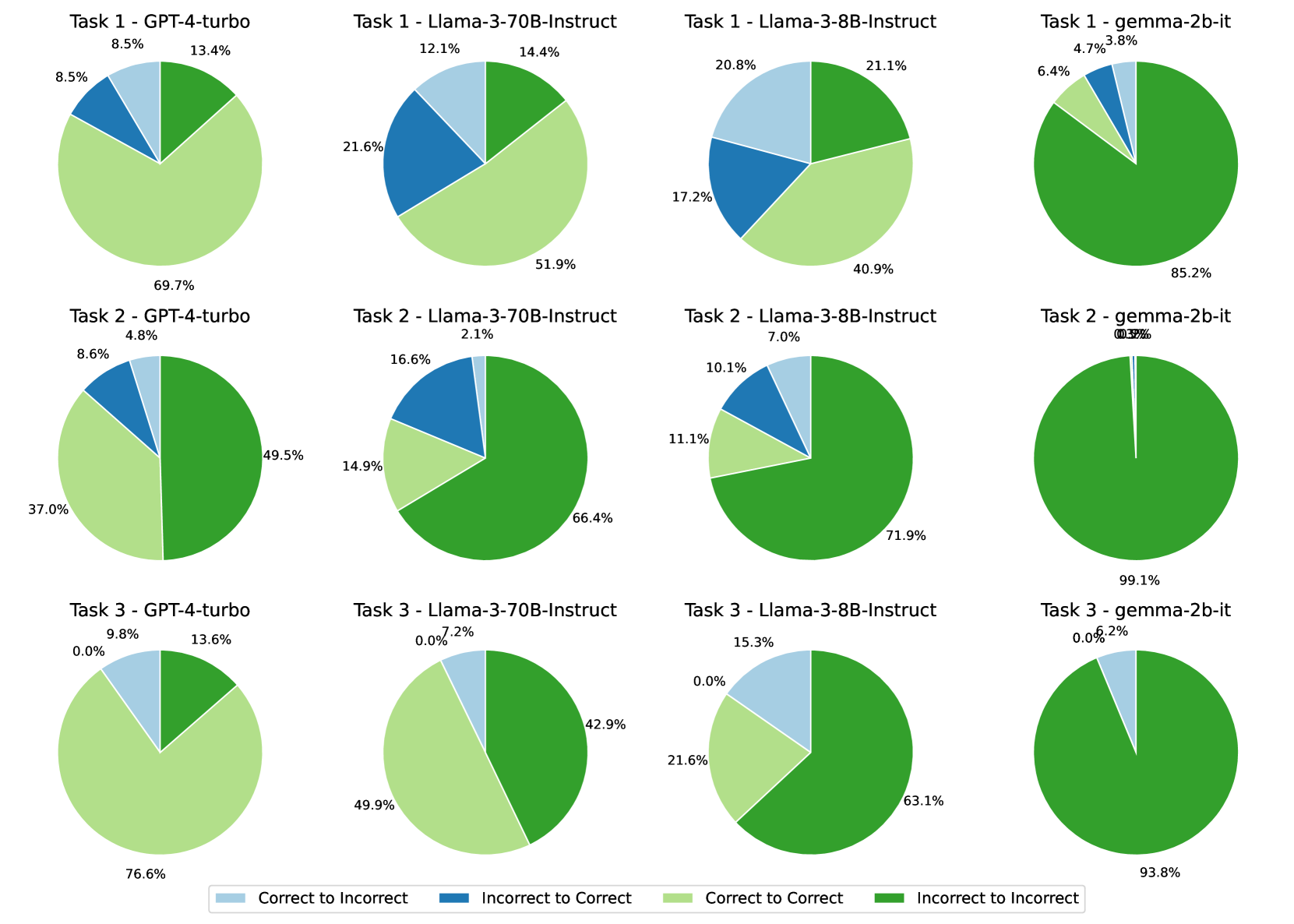
## Pie Chart Grid: AI Model Performance Across Tasks
### Overview
The image displays a 3x4 grid of pie charts comparing the performance of four AI models (GPT-4-turbo, Llama-3-70B-Instruct, Llama-3-8B-Instruct, gemma-2b-it) across three tasks. Each pie chart is divided into four colored segments representing transitions between correct/incorrect states. A legend at the bottom maps colors to transition types.
### Components/Axes
- **Legend**:
- Light Blue: Correct to Incorrect
- Dark Blue: Incorrect to Correct
- Light Green: Correct to Correct
- Dark Green: Incorrect to Incorrect
- **Grid Structure**:
- **Rows**: Task 1 (top), Task 2 (middle), Task 3 (bottom)
- **Columns**:
1. GPT-4-turbo
2. Llama-3-70B-Instruct
3. Llama-3-8B-Instruct
4. gemma-2b-it
### Detailed Analysis
#### Task 1
1. **GPT-4-turbo**:
- Correct to Incorrect: 8.5%
- Incorrect to Correct: 8.5%
- Correct to Correct: 13.4%
- Incorrect to Incorrect: 69.7%
2. **Llama-3-70B-Instruct**:
- Correct to Incorrect: 12.1%
- Incorrect to Correct: 21.6%
- Correct to Correct: 51.9%
- Incorrect to Incorrect: 14.4%
3. **Llama-3-8B-Instruct**:
- Correct to Incorrect: 20.8%
- Incorrect to Correct: 17.2%
- Correct to Correct: 40.9%
- Incorrect to Incorrect: 21.1%
4. **gemma-2b-it**:
- Correct to Incorrect: 4.7%
- Incorrect to Correct: 3.8%
- Correct to Correct: 6.4%
- Incorrect to Incorrect: 85.2%
#### Task 2
1. **GPT-4-turbo**:
- Correct to Incorrect: 4.8%
- Incorrect to Correct: 8.6%
- Correct to Correct: 37.0%
- Incorrect to Incorrect: 49.5%
2. **Llama-3-70B-Instruct**:
- Correct to Incorrect: 2.1%
- Incorrect to Correct: 16.6%
- Correct to Correct: 14.9%
- Incorrect to Incorrect: 66.4%
3. **Llama-3-8B-Instruct**:
- Correct to Incorrect: 10.1%
- Incorrect to Correct: 7.0%
- Correct to Correct: 11.1%
- Incorrect to Incorrect: 71.9%
4. **gemma-2b-it**:
- Correct to Incorrect: 0.3%
- Incorrect to Correct: 0.0%
- Correct to Correct: 99.1%
- Incorrect to Incorrect: 0.6%
#### Task 3
1. **GPT-4-turbo**:
- Correct to Incorrect: 0.0%
- Incorrect to Correct: 9.8%
- Correct to Correct: 76.6%
- Incorrect to Incorrect: 13.6%
2. **Llama-3-70B-Instruct**:
- Correct to Incorrect: 0.0%
- Incorrect to Correct: 7.2%
- Correct to Correct: 49.9%
- Incorrect to Incorrect: 42.9%
3. **Llama-3-8B-Instruct**:
- Correct to Incorrect: 0.0%
- Incorrect to Correct: 15.3%
- Correct to Correct: 21.6%
- Incorrect to Incorrect: 63.1%
4. **gemma-2b-it**:
- Correct to Incorrect: 0.0%
- Incorrect to Correct: 6.2%
- Correct to Correct: 93.8%
- Incorrect to Incorrect: 0.0%
### Key Observations
1. **gemma-2b-it Dominance**:
- Task 2: 99.1% Correct to Correct (highest consistency).
- Task 3: 93.8% Correct to Correct (strongest performance).
2. **GPT-4-turbo Trends**:
- Task 1: High Incorrect to Incorrect (69.7%) suggests poor handling of initial errors.
- Task 3: 76.6% Correct to Correct (best among models for Task 3).
3. **Llama Models**:
- Llama-3-70B-Instruct excels in Task 2 (66.4% Incorrect to Incorrect).
- Llama-3-8B-Instruct shows balanced transitions in Task 1 (21.1% Incorrect to Incorrect).
### Interpretation
- **Model Strengths**:
- gemma-2b-it demonstrates near-perfect consistency in Tasks 2 and 3, likely due to specialized training or architecture.
- GPT-4-turbo performs best in Task 3 but struggles with error propagation in Task 1.
- **Error Dynamics**:
- High Incorrect to Incorrect percentages (e.g., gemma-2b-it in Task 1: 85.2%) indicate models failing to recover from errors.
- Low Correct to Incorrect values (e.g., gemma-2b-it in Task 2: 0.3%) suggest robust error correction.
- **Anomalies**:
- Llama-3-70B-Instruct’s low Correct to Correct (14.9%) in Task 2 contrasts with its high Incorrect to Incorrect (66.4%), implying poor recovery from mistakes.
The data highlights task-specific model performance, with gemma-2b-it showing exceptional reliability in Tasks 2 and 3, while GPT-4-turbo and Llama models exhibit task-dependent variability.