TECHNICAL ASSET FINGERPRINT
d9fe2ecfd7a9855de5a0424e
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
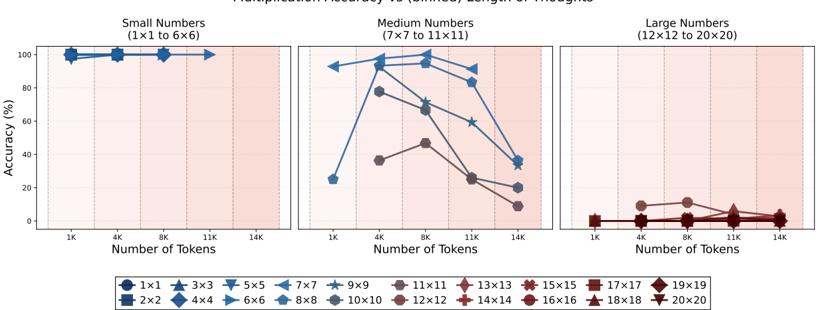
## Line Chart: Multiplication Accuracy vs. Number of Tokens (Context Length)
### Overview
The image displays a three-panel line chart titled "Multiplication Accuracy vs. (Context) Length of Images." It plots the accuracy percentage of a model performing matrix multiplication tasks against the number of tokens in the context. The data is segmented into three categories based on the size of the matrices being multiplied: Small, Medium, and Large Numbers. A comprehensive legend at the bottom maps specific matrix dimensions (e.g., 1x1, 3x3) to unique color and marker combinations.
### Components/Axes
* **Chart Type:** Three-panel line chart with markers.
* **Main Title:** "Multiplication Accuracy vs. (Context) Length of Images" (Note: The x-axis is labeled "Number of Tokens," suggesting "context length" is measured in tokens).
* **Panel Titles (Top):**
* Left Panel: "Small Numbers (1×1 to 6×6)"
* Center Panel: "Medium Numbers (7×7 to 11×11)"
* Right Panel: "Large Numbers (12×12 to 20×20)"
* **Y-Axis (All Panels):** Label: "Accuracy (%)". Scale: 0 to 100, with major ticks at 0, 20, 40, 60, 80, 100.
* **X-Axis (All Panels):** Label: "Number of Tokens". Discrete markers at: 1K, 4K, 8K, 11K, 14K.
* **Legend (Bottom Center):** A horizontal legend containing 20 entries, each pairing a matrix size with a unique color and marker shape. The entries are:
* 1x1 (Dark Blue Circle), 2x2 (Dark Blue Square), 3x3 (Blue Triangle Up), 4x4 (Blue Diamond), 5x5 (Light Blue Triangle Down), 6x6 (Light Blue Right Triangle), 7x7 (Light Blue Left Triangle), 8x8 (Light Blue Star), 9x9 (Light Blue Pentagon), 10x10 (Gray Circle), 11x11 (Brown Circle), 12x12 (Brown Diamond), 13x13 (Brown Triangle Up), 14x14 (Brown Plus), 15x15 (Brown Cross), 16x16 (Brown Hexagon), 17x17 (Brown Square), 18x18 (Brown Triangle Down), 19x19 (Brown Star), 20x20 (Brown Pentagon).
* **Background:** Each panel has a light pink shaded background.
### Detailed Analysis
**Panel 1: Small Numbers (1×1 to 6×6)**
* **Trend:** All data series (1x1 through 6x6) show consistently high accuracy, clustered near the top of the chart (90-100%).
* **Data Points (Approximate):**
* At 1K tokens: All series are at or very near 100% accuracy.
* At 4K tokens: Accuracy remains at ~100% for all.
* At 8K tokens: Accuracy remains at ~100% for all.
* At 11K tokens: Accuracy remains at ~100% for all.
* At 14K tokens: A slight, uniform dip is visible for all lines, dropping to approximately 95-98%.
**Panel 2: Medium Numbers (7×7 to 11×11)**
* **Trend:** This panel shows significant variation. Accuracy for most series peaks between 4K and 8K tokens before declining sharply as the number of tokens increases to 14K.
* **Data Points & Series Breakdown (Approximate):**
* **7x7 (Light Blue Left Triangle):** Starts at ~95% (1K), peaks at ~98% (4K), then declines to ~85% (8K), ~60% (11K), and ~35% (14K).
* **8x8 (Light Blue Star):** Follows a similar path to 7x7 but slightly lower: ~90% (1K), ~95% (4K), ~70% (8K), ~60% (11K), ~35% (14K).
* **9x9 (Light Blue Pentagon):** Starts lower: ~25% (1K), jumps to ~80% (4K), peaks at ~85% (8K), then drops to ~25% (11K) and ~20% (14K).
* **10x10 (Gray Circle):** Starts at ~38% (1K), rises to ~48% (4K), peaks at ~48% (8K), then falls to ~25% (11K) and ~10% (14K).
* **11x11 (Brown Circle):** The lowest in this group. Starts at ~38% (1K), rises to ~48% (4K), peaks at ~48% (8K), then falls to ~25% (11K) and ~10% (14K). (Note: The 10x10 and 11x11 lines appear to overlap closely).
**Panel 3: Large Numbers (12×12 to 20×20)**
* **Trend:** All data series show very low accuracy, generally below 20%, with no clear peak. Performance is poor across all context lengths.
* **Data Points (Approximate):** All lines (12x12 through 20x20) are clustered near the bottom of the chart.
* At 1K tokens: Accuracy is between ~0% and ~5%.
* At 4K tokens: A slight increase for some series, up to ~10-12%.
* At 8K tokens: Accuracy remains low, between ~5% and ~12%.
* At 11K tokens: Accuracy drops again, mostly below ~5%.
* At 14K tokens: Accuracy is near 0% for all series.
### Key Observations
1. **Clear Performance Stratification:** There is a stark, categorical difference in model performance based on matrix size. Small matrices are handled with near-perfect accuracy, medium matrices show context-dependent performance, and large matrices are handled very poorly.
2. **Context Length Sweet Spot:** For medium-sized matrices (7x7 to 11x11), accuracy is not monotonic. It generally improves from 1K to 4K/8K tokens before degrading significantly at longer contexts (11K, 14K).
3. **Universal Degradation at Long Context:** Across all panels, accuracy at 14K tokens is lower than at 8K tokens, indicating a general performance drop as context length approaches the upper limit shown.
4. **Large Matrix Failure:** The model appears fundamentally incapable of accurately performing multiplications for matrices 12x12 and larger within the tested context lengths, with accuracy never exceeding ~15%.
### Interpretation
This chart demonstrates the **scaling limitations** of the evaluated model on a specific arithmetic task (matrix multiplication). The data suggests:
* **Task Complexity vs. Model Capacity:** The model's ability to perform precise computation degrades sharply as the computational complexity of the task (matrix dimension) increases. Small multiplications are trivial, but larger ones likely exceed the model's effective "working memory" or procedural accuracy.
* **Context Window Utilization:** The peak in accuracy for medium matrices at 4K-8K tokens suggests an optimal context length for this task. Shorter contexts may lack sufficient information or examples, while longer contexts (11K-14K) may introduce noise, dilute attention, or exceed the model's reliable processing window, leading to performance collapse.
* **Fundamental Limitation:** The near-zero accuracy for large matrices indicates this is not merely a scaling issue but a fundamental limitation. The model likely does not learn the true algorithmic process for matrix multiplication but rather pattern-matches for smaller, more frequent cases. When the pattern becomes too complex (large matrices), it fails completely.
* **Practical Implication:** For applications requiring accurate arithmetic on larger data structures, this model would be unreliable. Its strength lies in processing smaller, perhaps more linguistic or symbolic, patterns within a moderate context window. The results highlight the difference between a model's ability to *recognize* patterns and its ability to *execute* precise, multi-step computations.
DECODING INTELLIGENCE...