## Flowchart: Citation Analysis Workflow
### Overview
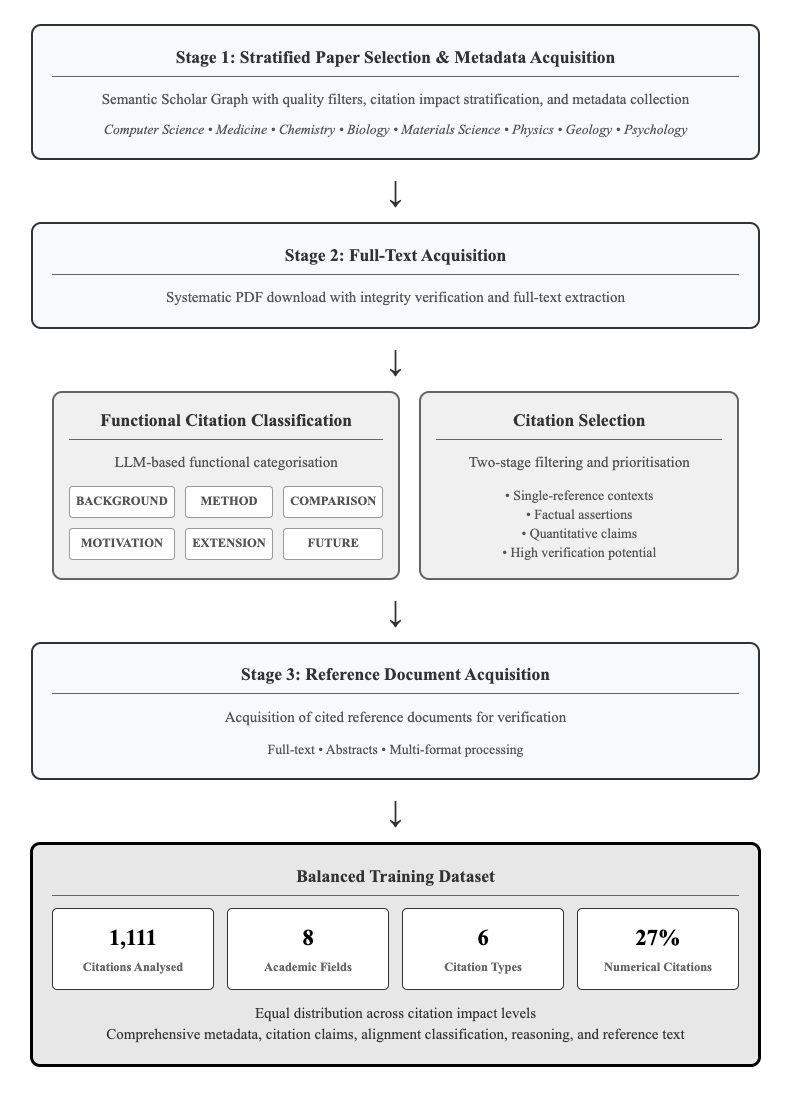
The image is a flowchart outlining a multi-stage process for citation analysis, starting from paper selection and metadata acquisition, proceeding through full-text acquisition and citation classification/selection, and culminating in reference document acquisition and the creation of a balanced training dataset.
### Components/Axes
* **Stages:** The flowchart is divided into three main stages, each represented by a rounded rectangle.
* **Flow Direction:** Arrows indicate the flow of the process from one stage to the next.
* **Functional Citation Classification:** A box detailing LLM-based functional categorization.
* **Citation Selection:** A box detailing two-stage filtering and prioritization.
* **Balanced Training Dataset:** A box summarizing the dataset characteristics.
### Detailed Analysis
**Stage 1: Stratified Paper Selection & Metadata Acquisition**
* Description: Semantic Scholar Graph with quality filters, citation impact stratification, and metadata collection.
* Disciplines: Computer Science, Medicine, Chemistry, Biology, Materials Science, Physics, Geology, Psychology.
**Stage 2: Full-Text Acquisition**
* Description: Systematic PDF download with integrity verification and full-text extraction.
**Functional Citation Classification**
* Description: LLM-based functional categorization.
* Categories:
* BACKGROUND
* METHOD
* COMPARISON
* MOTIVATION
* EXTENSION
* FUTURE
**Citation Selection**
* Description: Two-stage filtering and prioritization.
* Criteria:
* Single-reference contexts
* Factual assertions
* Quantitative claims
* High verification potential
**Stage 3: Reference Document Acquisition**
* Description: Acquisition of cited reference documents for verification.
* Formats: Full-text, Abstracts, Multi-format processing.
**Balanced Training Dataset**
* Citations Analysed: 1,111
* Academic Fields: 8
* Citation Types: 6
* Numerical Citations: 27%
* Additional Information: Equal distribution across citation impact levels. Comprehensive metadata, citation claims, alignment classification, reasoning, and reference text.
### Key Observations
* The process is sequential, moving from broad paper selection to detailed reference document acquisition.
* LLM-based functional categorization is used for citation classification.
* Citation selection involves a two-stage filtering and prioritization process.
* The final dataset is balanced across citation impact levels.
### Interpretation
The flowchart describes a systematic approach to building a citation analysis dataset. The process begins with a broad selection of papers from Semantic Scholar, filtered by quality and citation impact. Full texts are then acquired and processed. Citations are classified using an LLM-based approach, categorized by function (e.g., background, method, comparison). A two-stage filtering process selects relevant citations based on criteria such as single-reference contexts and factual assertions. Finally, reference documents are acquired for verification, and a balanced training dataset is created. The dataset includes a large number of citations (1,111), spans multiple academic fields (8), and includes various citation types (6). The 27% numerical citations suggests a focus on quantitative research. The equal distribution across citation impact levels indicates an effort to avoid bias in the dataset.