\n
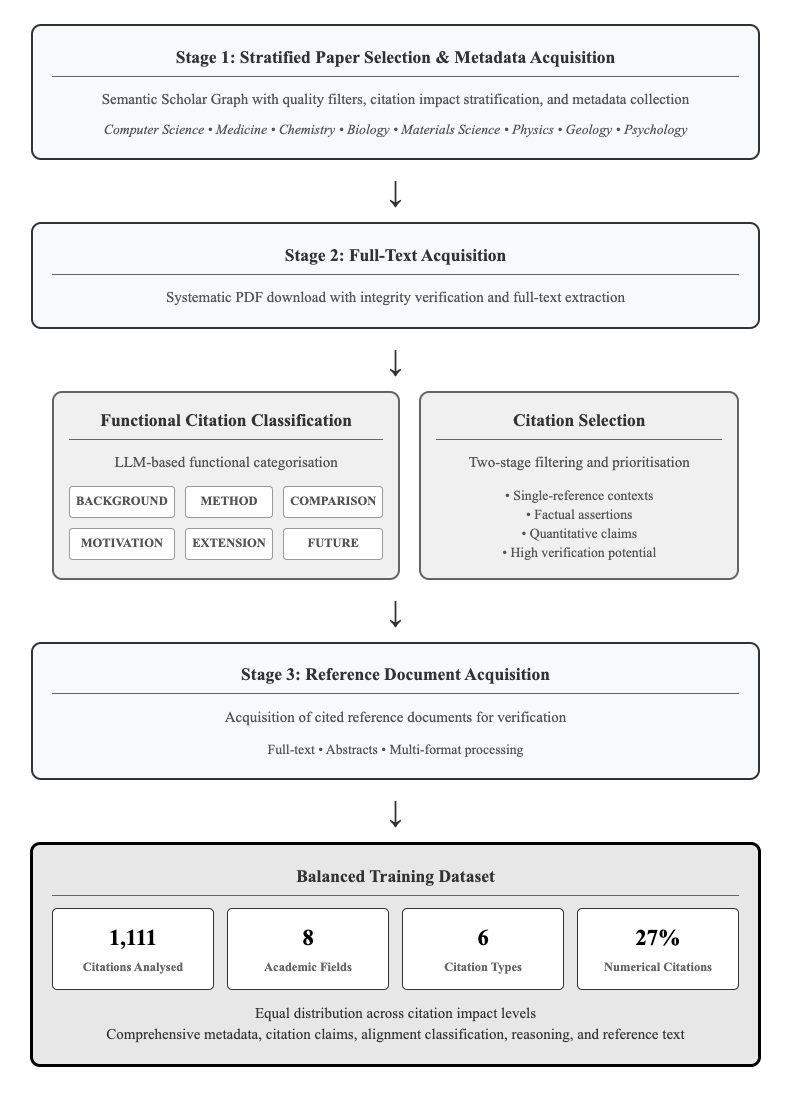
## Diagram: Research Pipeline for Balanced Training Dataset
### Overview
This diagram illustrates a four-stage research pipeline for creating a balanced training dataset, starting from paper selection and metadata acquisition, progressing through full-text acquisition and functional citation classification, and culminating in reference document acquisition and dataset creation. The diagram uses a flowchart style with rectangular boxes representing stages and arrows indicating the flow of information.
### Components/Axes
The diagram is structured into four main stages, each with a descriptive title. The stages are:
1. Stage 1: Stratified Paper Selection & Metadata Acquisition
2. Stage 2: Full-Text Acquisition
3. Stage 3: Reference Document Acquisition
4. Balanced Training Dataset (bottom section)
Within Stage 1, the following academic fields are listed: Computer Science, Medicine, Chemistry, Biology, Materials Science, Physics, Geology, and Psychology.
Stage 2 contains only text.
Stage 3 contains text describing the acquisition process.
The "Functional Citation Classification" section within Stage 2 includes the following categories, represented by colored boxes: BACKGROUND (light blue), METHOD (orange), COMPARISON (light green), MOTIVATION (purple), EXTENSION (yellow), FUTURE (red).
The "Citation Selection" section within Stage 2 lists the following criteria: Single-reference contexts, Factual assertions, Quantitative claims, High verification potential.
The "Balanced Training Dataset" section at the bottom displays the following numerical data: 1,111 Citations Analysed, 8 Academic Fields, 6 Citation Types, 27% Numerical Citations. It also includes text indicating "Equal distribution across citation impact levels" and "Comprehensive metadata, citation claims, alignment classification, reasoning, and reference text".
### Detailed Analysis or Content Details
The diagram flows sequentially from top to bottom.
**Stage 1:** The initial stage focuses on selecting papers from various academic fields (listed above) using quality filters, impact stratification, and metadata collection.
**Stage 2:** This stage involves downloading papers in PDF format, verifying their integrity, and extracting the full text. Within this stage, citations are classified based on their function (BACKGROUND, METHOD, COMPARISON, MOTIVATION, EXTENSION, FUTURE) using an LLM-based categorization. Simultaneously, citations are selected based on criteria like single-reference contexts and verification potential.
**Stage 3:** The third stage involves acquiring the cited reference documents for verification, including full text and abstracts, and processing them in multiple formats.
**Balanced Training Dataset:** The final section presents the characteristics of the resulting dataset: 1,111 citations were analyzed, representing 8 academic fields, 6 citation types, with 27% of the citations being numerical. The dataset is designed to have an equal distribution across citation impact levels and includes comprehensive metadata.
### Key Observations
The pipeline emphasizes a systematic and rigorous approach to dataset creation, incorporating quality control measures at each stage. The use of LLM-based functional citation classification is a key feature. The dataset appears to be diverse, covering multiple academic fields and citation types. The emphasis on numerical citations (27%) suggests a focus on quantitative analysis.
### Interpretation
This diagram outlines a robust methodology for building a high-quality, balanced training dataset for research purposes, likely related to natural language processing or information retrieval. The pipeline's strength lies in its multi-stage approach, combining automated processes (LLM-based classification) with human verification (acquisition of reference documents). The inclusion of metadata, citation claims, and alignment classification suggests a focus on understanding the relationships between papers and their cited references. The balanced distribution across citation impact levels is crucial for avoiding bias in downstream applications. The pipeline is designed to create a dataset that is not only large (1,111 citations) but also rich in information and representative of diverse academic fields. The emphasis on "verification potential" suggests a focus on creating a dataset suitable for tasks requiring high accuracy and reliability.