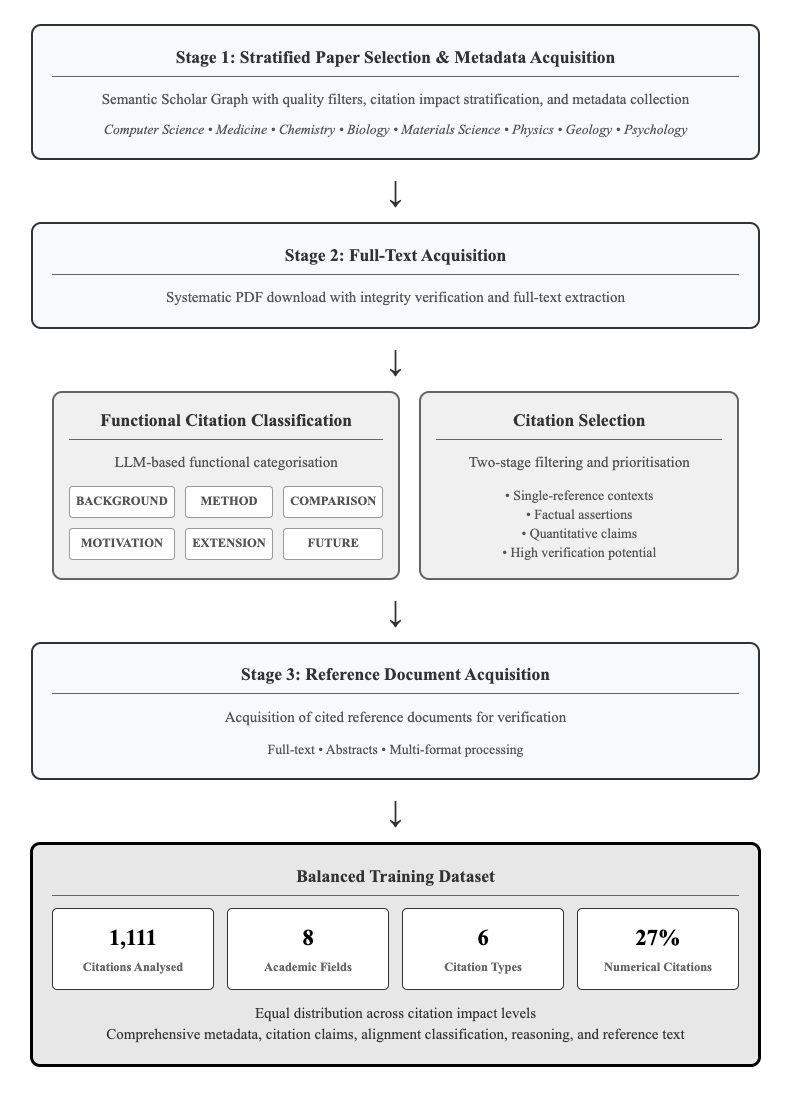
## Flowchart: Research Paper Processing and Citation Analysis Workflow
### Overview
The image displays a vertical flowchart outlining a four-stage systematic process for acquiring, processing, and categorizing academic papers and their citations to create a balanced training dataset. The workflow progresses from top to bottom, with one stage splitting into two parallel processes before converging again.
### Components/Axes
The diagram consists of four primary rectangular stages connected by downward-pointing arrows, indicating sequential flow. The third stage is split into two parallel, side-by-side boxes.
**Stage 1: Stratified Paper Selection & Metadata Acquisition**
- **Process:** Semantic Scholar Graph with quality filters, citation impact stratification, and metadata collection.
- **Academic Fields Listed:** Computer Science • Medicine • Chemistry • Biology • Materials Science • Physics • Geology • Psychology
**Stage 2: Full-Text Acquisition**
- **Process:** Systematic PDF download with integrity verification and full-text extraction.
**Parallel Processes (Following Stage 2):**
1. **Functional Citation Classification**
- **Method:** LLM-based functional categorisation.
- **Citation Function Categories (in boxes):** BACKGROUND, METHOD, COMPARISON, MOTIVATION, EXTENSION, FUTURE.
2. **Citation Selection**
- **Method:** Two-stage filtering and prioritisation.
- **Selection Criteria (bullet points):**
- Single-reference contexts
- Factual assertions
- Quantitative claims
- High verification potential
**Stage 3: Reference Document Acquisition**
- **Process:** Acquisition of cited reference documents for verification.
- **Formats Processed:** Full-text • Abstracts • Multi-format processing
**Final Output: Balanced Training Dataset**
This final box contains four key metrics presented in individual sub-boxes:
- **1,111** Citations Analysed
- **8** Academic Fields
- **6** Citation Types
- **27%** Numerical Citations
- **Additional Notes:** Equal distribution across citation impact levels. Comprehensive metadata, citation claims, alignment classification, reasoning, and reference text.
### Detailed Analysis
The workflow is a linear pipeline with a bifurcation for specialized processing. The initial stage casts a wide net across eight major scientific disciplines. The core processing involves two complementary actions on the acquired full-texts: classifying the *function* of citations (e.g., to provide background or propose future work) and *selecting* citations based on their verifiability (prioritizing factual and quantitative claims). The process concludes by acquiring the referenced documents themselves and compiling all information into a structured dataset characterized by specific quantitative metrics (1,111 citations, 27% numerical) and qualitative balance (across fields and impact levels).
### Key Observations
1. **Multi-Disciplinary Scope:** The process explicitly targets eight distinct academic fields, ensuring broad coverage.
2. **LLM Integration:** Large Language Models are specified as the tool for the functional classification task.
3. **Verification Focus:** The "Citation Selection" criteria heavily emphasize verifiable content (factual assertions, quantitative claims).
4. **Dataset Composition:** The final dataset is defined by precise numbers: 1,111 citations from 8 fields, categorized into 6 types, with a notable 27% being numerical citations.
5. **Parallel Processing:** The workflow intelligently separates the *analysis* of citation function from the *selection* of citations for verification, allowing these tasks to proceed concurrently after full-text acquisition.
### Interpretation
This flowchart details a rigorous, automated methodology for constructing a high-quality, verifiable citation analysis dataset. The process is designed to move from broad acquisition to highly specific selection and classification.
The **Peircean investigative reading** suggests this is a system built for **abductive reasoning**—it doesn't just collect data but actively selects elements (factual/quantitative claims) that are most suitable for generating and testing hypotheses about scientific discourse. The emphasis on "verification potential" and the acquisition of reference documents indicates the ultimate goal is likely to train or evaluate models on their ability to fact-check or validate scientific claims against source material.
The **balanced nature** of the final dataset (across fields and impact levels) is critical for ensuring any model trained on it generalizes well and doesn't inherit biases toward specific disciplines or citation popularity. The 27% figure for numerical citations highlights a targeted focus on quantitative scientific claims, which are often central to verification tasks. This workflow represents a sophisticated pipeline for creating ground-truth data to advance research in automated scientific claim verification, citation analysis, and scholarly document understanding.