## Flowchart: Research Methodology for Citation Analysis
### Overview
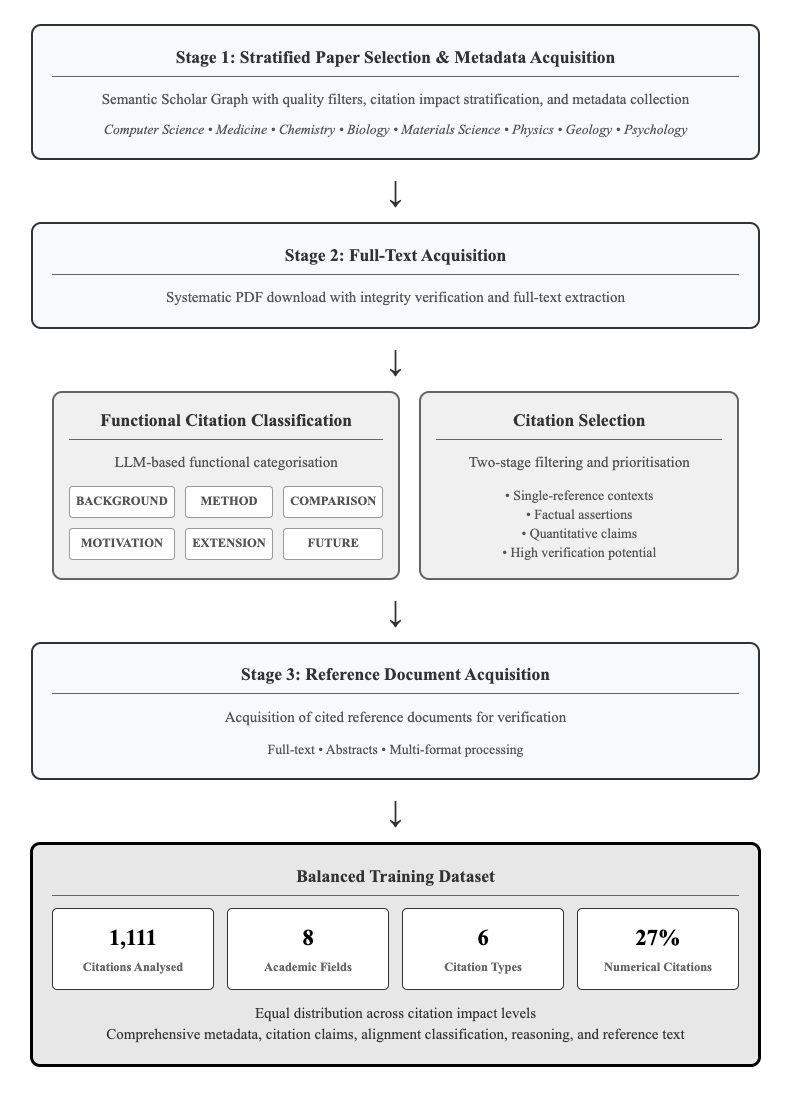
The flowchart outlines a four-stage research methodology for citation analysis, progressing from paper selection to dataset creation. It includes functional classification of citations, reference document acquisition, and a balanced training dataset summary.
### Components/Axes
1. **Stages** (Vertical Flow):
- Stage 1: Stratified Paper Selection & Metadata Acquisition
- Stage 2: Full-Text Acquisition
- Stage 3: Reference Document Acquisition
- Balanced Training Dataset (Bottom Section)
2. **Sub-Components**:
- Functional Citation Classification (Left Box)
- Citation Selection (Right Box)
3. **Dataset Metrics** (Bottom Section):
- Citations Analyzed: 1,111
- Academic Fields: 8
- Citation Types: 6
- Numerical Citations: 27%
### Detailed Analysis
#### Stage 1: Stratified Paper Selection & Metadata Acquisition
- Uses Semantic Scholar Graph with quality filters
- Citation impact stratification applied
- Metadata collected across 8 academic fields:
- Computer Science
- Medicine
- Chemistry
- Biology
- Materials Science
- Physics
- Geology
- Psychology
#### Stage 2: Full-Text Acquisition
- Systematic PDF download with integrity verification
- Full-text extraction performed
#### Functional Citation Classification
- LLM-based categorization into 6 types:
- BACKGROUND
- METHOD
- COMPARISON
- MOTIVATION
- EXTENSION
- FUTURE
#### Citation Selection
- Two-stage filtering and prioritization:
- Single-reference contexts
- Factual assertions
- Quantitative claims
- High verification potential
#### Stage 3: Reference Document Acquisition
- Acquires cited reference documents for verification
- Processes:
- Full-text
- Abstracts
- Multi-format processing
#### Balanced Training Dataset
- **Quantitative Metrics**:
- 1,111 citations analyzed
- 8 academic fields represented
- 6 citation types included
- 27% numerical citations
- **Qualitative Features**:
- Equal distribution across citation impact levels
- Comprehensive metadata
- Citation claims
- Alignment classification
- Reasoning
- Reference text
### Key Observations
1. **Structured Progression**: Methodology follows a logical flow from paper selection to dataset creation
2. **LLM Integration**: Machine learning used for citation classification
3. **Field Diversity**: Covers 8 distinct academic disciplines
4. **Citation Balance**: 27% numerical citations suggest focus on quantitative analysis
5. **Multi-format Processing**: Accommodates various document types in reference acquisition
### Interpretation
This methodology demonstrates a systematic approach to building a citation analysis dataset:
1. **Data Curation**: Stages 1-3 ensure high-quality, verified data collection through multiple filters (citation impact, verification potential)
2. **LLM Utilization**: Functional classification leverages machine learning for efficient categorization
3. **Dataset Balance**: The 27% numerical citations and equal distribution across impact levels suggest careful balancing for model training
4. **Interdisciplinary Scope**: Coverage of 8 fields indicates broad applicability potential
The methodology appears designed to create a robust training dataset for citation analysis models, with particular emphasis on quantitative claims and verification potential. The inclusion of multi-format processing and comprehensive metadata suggests preparation for complex NLP tasks.