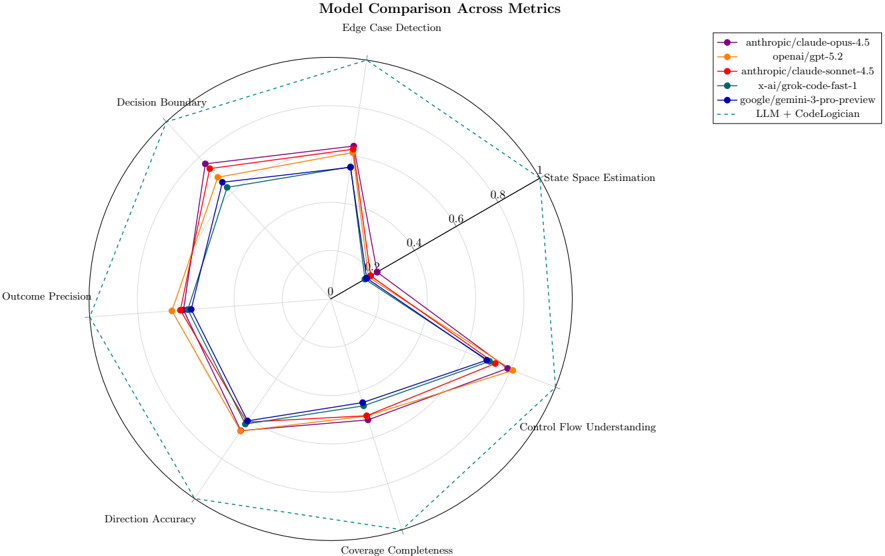
## Radar Chart: Model Comparison Across Metrics
### Overview
The chart compares six AI models across seven technical metrics using a radar chart format. Models are represented by colored lines, with a dashed benchmark line (LLM + CodeLogician) for reference. The circular layout shows performance distribution across metrics, with radial distance indicating metric strength (0-1.0 scale).
### Components/Axes
- **Axes (clockwise from top):**
1. Edge Case Detection
2. Decision Boundary
3. Outcome Precision
4. Direction Accuracy
5. Coverage Completeness
6. Control Flow Understanding
7. State Space Estimation
- **Radial Scale:** 0.0 (center) to 1.0 (outer edge) in 0.2 increments
- **Legend (top-right):**
- Purple: anthropic/claude-opus-4.5
- Orange: openai/gpt-5.2
- Red: anthropic/claude-sonnet-4.5
- Teal: x-ai/grok-code-fast-1
- Blue: google/gemini-3-pro-preview
- Dashed: LLM + CodeLogician (benchmark)
### Detailed Analysis
1. **anthropic/claude-opus-4.5 (Purple):**
- Peaks at 0.85 in Edge Case Detection
- Strong in Decision Boundary (0.78) and Outcome Precision (0.72)
- Weakest in State Space Estimation (0.35)
2. **openai/gpt-5.2 (Orange):**
- Highest in Control Flow Understanding (0.92)
- Strong in Direction Accuracy (0.81) and Coverage Completeness (0.76)
- Moderate in Edge Case Detection (0.68)
3. **anthropic/claude-sonnet-4.5 (Red):**
- Matches Opus in Edge Case Detection (0.85)
- Strong in State Space Estimation (0.78)
- Weakest in Direction Accuracy (0.42)
4. **x-ai/grok-code-fast-1 (Teal):**
- Balanced performance (0.65-0.75 range)
- Weakest in State Space Estimation (0.48)
5. **google/gemini-3-pro-preview (Blue):**
- Most consistent performance (0.58-0.72 range)
- Strongest in Coverage Completeness (0.72)
6. **LLM + CodeLogician (Dashed):**
- Benchmark line at 0.65-0.80 range
- No model consistently exceeds this across all metrics
### Key Observations
- **Specialization vs. Generalization:** Models show clear specialization:
- Opus and Sonnet excel in Edge Case Detection
- GPT-5.2 dominates Control Flow Understanding
- Gemini shows balanced but unspectacular performance
- **Benchmark Gap:** All models fall short of the LLM + CodeLogician benchmark in at least one metric
- **State Space Estimation Weakness:** All models score below 0.8 in this metric
- **Direction Accuracy Variance:** Ranges from 0.42 (Sonnet) to 0.81 (GPT-5.2)
### Interpretation
The chart reveals fundamental trade-offs in AI model capabilities:
1. **Edge Case Masters (Opus/Sonnet):** Prioritize robustness in unusual scenarios but struggle with state space modeling
2. **Control Flow Specialists (GPT-5.2):** Excel at code structure analysis but lag in precision metrics
3. **Balanced Performers (Gemini):** Offer moderate capability across metrics but lack standout strengths
4. **Benchmark Significance:** The LLM + CodeLogician line suggests that combining models could potentially achieve more balanced performance, though current implementations show diminishing returns in certain areas.
Notably, the State Space Estimation metric appears to be a universal weakness, possibly indicating a fundamental challenge in current AI architectures for modeling complex state transitions. The Direction Accuracy variance suggests differing approaches to code navigation tasks between model architectures.