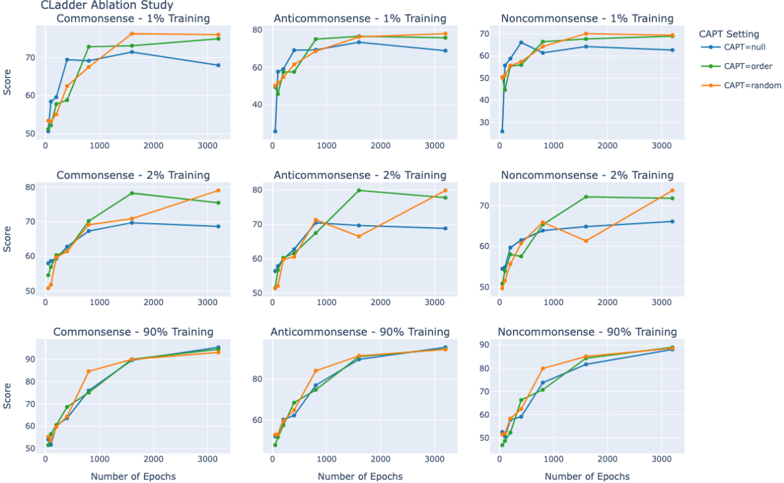
\n
## Line Chart: Ladder Ablation Study
### Overview
The image presents a 3x3 grid of line charts, visualizing the results of a "Ladder Ablation Study". Each chart displays the "Score" against the "Number of Epochs" for different "CAPT Setting" configurations. The study appears to investigate the impact of varying amounts of training data (1%, 2%, and 90%) across three categories: "Commonsense", "Anticommonsense", and "Noncommonsense".
### Components/Axes
* **Title:** "Ladder Ablation Study" (top-center)
* **X-axis Label:** "Number of Epochs" (present on all charts) - Scale ranges from approximately 0 to 3000.
* **Y-axis Label:** "Score" (present on all charts) - Scale ranges from approximately 30 to 90.
* **Legend:** Located in the top-right corner of each chart, with the following entries:
* CAPT=null (Blue Line)
* CAPT=random (Green Line)
* CAPT=random (Orange Line)
* **Sub-Titles:** Each chart has a sub-title indicating the category and training percentage, e.g., "Commonsense - 1% Training".
### Detailed Analysis or Content Details
Here's a breakdown of each chart, noting trends and approximate data points.
**Row 1: 1% Training**
* **Commonsense - 1% Training:**
* CAPT=null (Blue): Starts at ~52, rises to ~72 at 1000 epochs, plateaus around ~73.
* CAPT=random (Green): Starts at ~52, rises steadily to ~74 at 3000 epochs.
* CAPT=random (Orange): Starts at ~52, rises to ~72 at 1000 epochs, plateaus around ~72.
* **Anticommonsense - 1% Training:**
* CAPT=null (Blue): Starts at ~35, rises rapidly to ~68 at 1000 epochs, then plateaus around ~68.
* CAPT=random (Green): Starts at ~35, rises steadily to ~65 at 3000 epochs.
* CAPT=random (Orange): Starts at ~35, rises to ~60 at 1000 epochs, then plateaus around ~60.
* **Noncommonsense - 1% Training:**
* CAPT=null (Blue): Starts at ~65, rises to ~72 at 1000 epochs, then fluctuates around ~70.
* CAPT=random (Green): Starts at ~65, rises to ~70 at 1000 epochs, then fluctuates around ~70.
* CAPT=random (Orange): Starts at ~65, rises to ~68 at 1000 epochs, then fluctuates around ~68.
**Row 2: 2% Training**
* **Commonsense - 2% Training:**
* CAPT=null (Blue): Starts at ~55, rises to ~78 at 1000 epochs, then plateaus around ~78.
* CAPT=random (Green): Starts at ~55, rises steadily to ~80 at 3000 epochs.
* CAPT=random (Orange): Starts at ~55, rises to ~75 at 1000 epochs, then plateaus around ~75.
* **Anticommonsense - 2% Training:**
* CAPT=null (Blue): Starts at ~40, rises rapidly to ~70 at 1000 epochs, then plateaus around ~70.
* CAPT=random (Green): Starts at ~40, rises steadily to ~68 at 3000 epochs.
* CAPT=random (Orange): Starts at ~40, rises to ~62 at 1000 epochs, then plateaus around ~62.
* **Noncommonsense - 2% Training:**
* CAPT=null (Blue): Starts at ~68, rises to ~73 at 1000 epochs, then fluctuates around ~72.
* CAPT=random (Green): Starts at ~68, rises to ~72 at 1000 epochs, then fluctuates around ~72.
* CAPT=random (Orange): Starts at ~68, rises to ~70 at 1000 epochs, then fluctuates around ~70.
**Row 3: 90% Training**
* **Commonsense - 90% Training:**
* CAPT=null (Blue): Starts at ~52, rises to ~88 at 1000 epochs, then plateaus around ~88.
* CAPT=random (Green): Starts at ~52, rises steadily to ~92 at 3000 epochs.
* CAPT=random (Orange): Starts at ~52, rises to ~85 at 1000 epochs, then plateaus around ~85.
* **Anticommonsense - 90% Training:**
* CAPT=null (Blue): Starts at ~45, rises rapidly to ~82 at 1000 epochs, then plateaus around ~82.
* CAPT=random (Green): Starts at ~45, rises steadily to ~80 at 3000 epochs.
* CAPT=random (Orange): Starts at ~45, rises to ~75 at 1000 epochs, then plateaus around ~75.
* **Noncommonsense - 90% Training:**
* CAPT=null (Blue): Starts at ~65, rises to ~85 at 1000 epochs, then plateaus around ~85.
* CAPT=random (Green): Starts at ~65, rises to ~83 at 1000 epochs, then plateaus around ~83.
* CAPT=random (Orange): Starts at ~65, rises to ~80 at 1000 epochs, then plateaus around ~80.
### Key Observations
* **Training Data Impact:** Increasing the training data (from 1% to 90%) consistently improves the score across all categories and CAPT settings.
* **CAPT=null Performance:** The "CAPT=null" setting generally achieves the highest scores, particularly with higher training data percentages.
* **CAPT=random Convergence:** The "CAPT=random" setting shows a more gradual increase in score, but eventually converges towards similar levels as "CAPT=null" with sufficient training.
* **Anticommonsense Lag:** The "Anticommonsense" category consistently has lower scores compared to "Commonsense" and "Noncommonsense", even with 90% training.
* **Plateau Effect:** Most lines plateau after approximately 1000-2000 epochs, indicating diminishing returns from further training.
### Interpretation
The data suggests that the "Ladder Ablation Study" is evaluating the effectiveness of different CAPT (presumably Contrastive Alignment Pre-Training) settings on model performance across various types of knowledge. The results indicate that CAPT is beneficial, with the "null" setting performing best, and that more training data leads to better performance. The consistent lower scores in the "Anticommonsense" category suggest that this type of knowledge is more difficult for the model to acquire, potentially due to its inherent complexity or scarcity in the training data. The plateau effect observed in most lines indicates that the model reaches a point of diminishing returns, and further training may not significantly improve performance. This study provides valuable insights into the impact of CAPT and training data on model performance, and can inform future research and development efforts. The consistent performance of CAPT=null suggests that a baseline without specific contrastive alignment is surprisingly effective, and the study could be extended to explore more sophisticated CAPT strategies.