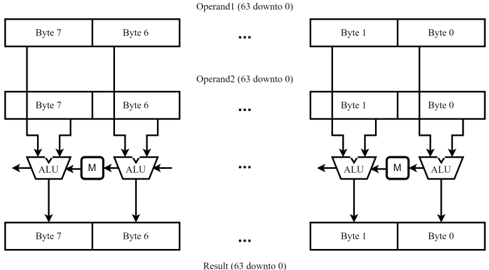
## Diagram: Parallel ALU Processing Pipeline
### Overview
The diagram illustrates a dual-parallel processing pipeline architecture with two identical processing units (left and right). Each unit contains two Arithmetic Logic Units (ALUs) and a multiplier (M), processing 8-bit operand pairs (Byte 7/6 and Byte 1/0) through a cascaded computation flow. Results accumulate at the bottom of each pipeline.
### Components/Axes
- **Left Pipeline**:
- **Operand1**: Labeled "Operand1 (63 downto 0)" spanning Bytes 7-6
- **Operand2**: Labeled "Operand2 (63 downto 0)" spanning Bytes 7-6
- **Processing Units**: Two ALUs and one multiplier (M) arranged vertically
- **Result**: Labeled "Result (63 downto 0)" at the bottom
- **Right Pipeline**:
- **Operand1**: Labeled "Operand1 (63 downto 0)" spanning Bytes 1-0
- **Operand2**: Labeled "Operand2 (63 downto 0)" spanning Bytes 1-0
- **Processing Units**: Identical ALU/M configuration to left pipeline
- **Result**: Labeled "Result (63 downto 0)" at the bottom
- **Data Flow**: Arrows indicate downward processing direction (63→0) through each pipeline stage
### Detailed Analysis
1. **Operand Structure**:
- Both pipelines process 64-bit operands split across two bytes:
- Left: Bytes 7 (MSB) and 6
- Right: Bytes 1 and 0 (LSB)
- Each operand spans 64 bits (63 downto 0) despite being represented across two 8-bit bytes
2. **Processing Units**:
- ALUs positioned above multiplier (M) in both pipelines
- Vertical stacking suggests sequential processing stages
- Mirrored architecture between left/right pipelines
3. **Result Accumulation**:
- Final results occupy full 64-bit width (63 downto 0)
- Implies concatenation or aggregation of intermediate results
### Key Observations
- **Symmetry**: Identical pipeline configurations on both sides
- **Byte Mapping**: Operand bytes map to different memory/register locations (7-6 vs 1-0)
- **Bit Width Consistency**: All operands and results maintain 64-bit width despite byte-level representation
- **Multiplier Positioning**: M unit acts as intermediary between ALUs in processing flow
### Interpretation
This architecture demonstrates a **parallel computation framework** optimized for:
1. **High-throughput arithmetic operations** through dual ALU processing
2. **Memory efficiency** by utilizing adjacent byte pairs (7-6 and 1-0)
3. **Modular design** with identical processing units enabling scalable expansion
The downward data flow (63→0) suggests **big-endian byte ordering** implementation. The presence of both ALUs and a multiplier in each pipeline indicates **mixed-precision computation capabilities**, potentially supporting both integer and floating-point operations through ALUs while handling specialized multiplications via dedicated hardware.
The mirrored pipeline design allows **simultaneous processing of two data segments**, effectively doubling computational throughput while maintaining identical result formatting. This could be particularly valuable in applications requiring:
- Vector/matrix operations
- Cryptographic computations
- Signal processing pipelines