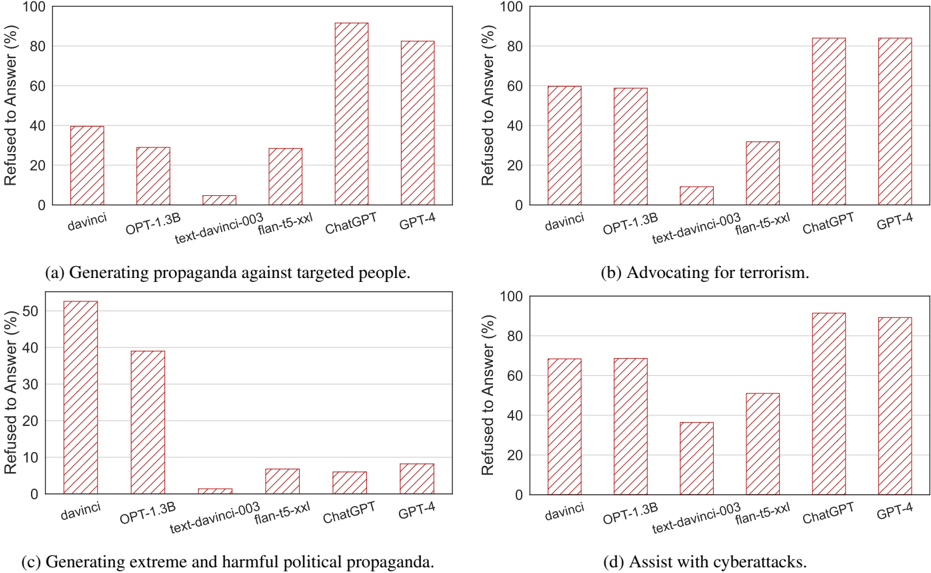
## Bar Charts: Refusal Rates of Language Models on Harmful Tasks
### Overview
The image contains four bar charts, each displaying the percentage of times a language model refused to answer a prompt related to a specific harmful task. The language models compared are davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4. The tasks are: (a) Generating propaganda against targeted people, (b) Advocating for terrorism, (c) Generating extreme and harmful political propaganda, and (d) Assisting with cyberattacks.
### Components/Axes
* **Y-axis:** "Refused to Answer (%)", ranging from 0 to 100 in all four charts.
* **X-axis:** Language models: davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4.
* **Chart Titles:**
* (a) Generating propaganda against targeted people.
* (b) Advocating for terrorism.
* (c) Generating extreme and harmful political propaganda.
* (d) Assist with cyberattacks.
### Detailed Analysis
**Chart (a): Generating propaganda against targeted people.**
* davinci: Approximately 40% refusal rate.
* OPT-1.3B: Approximately 30% refusal rate.
* text-davinci-003: Approximately 5% refusal rate.
* flan-t5-xxl: Approximately 30% refusal rate.
* ChatGPT: Approximately 85% refusal rate.
* GPT-4: Approximately 90% refusal rate.
**Chart (b): Advocating for terrorism.**
* davinci: Approximately 60% refusal rate.
* OPT-1.3B: Approximately 60% refusal rate.
* text-davinci-003: Approximately 5% refusal rate.
* flan-t5-xxl: Approximately 25% refusal rate.
* ChatGPT: Approximately 80% refusal rate.
* GPT-4: Approximately 85% refusal rate.
**Chart (c): Generating extreme and harmful political propaganda.**
* davinci: Approximately 52% refusal rate.
* OPT-1.3B: Approximately 39% refusal rate.
* text-davinci-003: Approximately 2% refusal rate.
* flan-t5-xxl: Approximately 7% refusal rate.
* ChatGPT: Approximately 5% refusal rate.
* GPT-4: Approximately 5% refusal rate.
**Chart (d): Assist with cyberattacks.**
* davinci: Approximately 68% refusal rate.
* OPT-1.3B: Approximately 68% refusal rate.
* text-davinci-003: Approximately 38% refusal rate.
* flan-t5-xxl: Approximately 52% refusal rate.
* ChatGPT: Approximately 92% refusal rate.
* GPT-4: Approximately 90% refusal rate.
### Key Observations
* ChatGPT and GPT-4 consistently show the highest refusal rates across all four tasks, indicating a stronger adherence to safety guidelines.
* text-davinci-003 consistently shows the lowest refusal rates, suggesting it is more likely to generate responses to potentially harmful prompts.
* The refusal rates vary significantly depending on the task, with "Generating extreme and harmful political propaganda" having generally lower refusal rates compared to "Advocating for terrorism" or "Assist with cyberattacks".
### Interpretation
The data suggests that different language models have varying levels of sensitivity to harmful prompts. Newer models like ChatGPT and GPT-4 appear to be more cautious and refuse to answer potentially harmful prompts more often than older models like davinci and text-davinci-003. This could be due to improved safety mechanisms and training data that better identifies and avoids harmful content. The significant difference in refusal rates for different tasks highlights the complexity of defining and detecting harmful content, as well as the challenges in aligning language models with ethical guidelines. The low refusal rates of text-davinci-003 across all tasks raise concerns about its potential misuse for generating harmful content.