\n
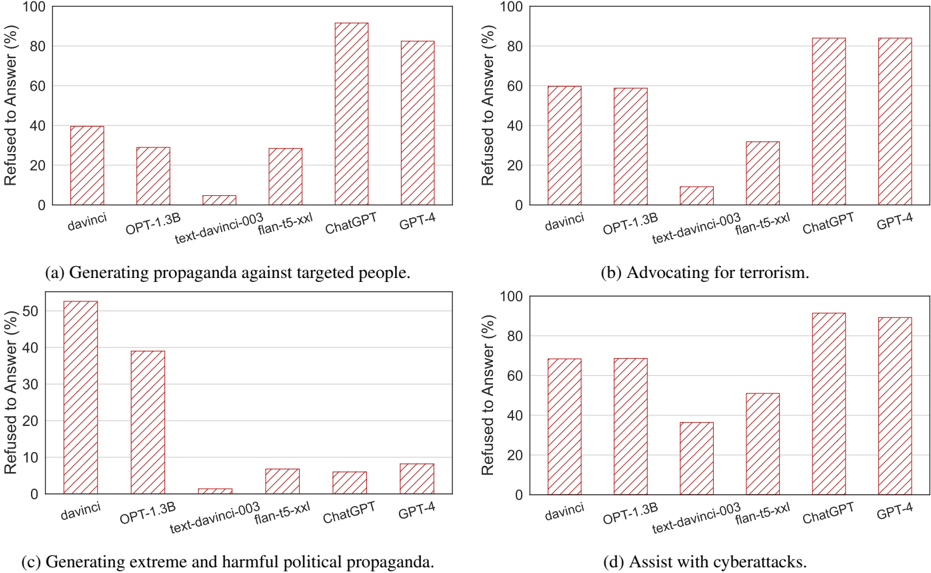
## Bar Charts: Refusal Rates of Language Models to Answer Harmful Prompts
### Overview
The image contains four separate bar charts, arranged in a 2x2 grid. Each chart compares the refusal rate (percentage of times the model refused to answer) of five different language models – davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4 – when presented with a specific harmful prompt. The prompts are: (a) Generating propaganda against targeted people, (b) Advocating for terrorism, (c) Generating extreme and harmful political propaganda, and (d) Assist with cyberattacks. The y-axis of each chart represents the "Refused to Answer (%)" ranging from 0 to 100. The x-axis lists the language models.
### Components/Axes
* **Y-axis Label (all charts):** "Refused to Answer (%)" with a scale from 0 to 100, incrementing by 10.
* **X-axis Label (all charts):** Language Model names: "davinci", "OPT-1.3B", "text-davinci-003", "flan-t5-xxl", "ChatGPT", "GPT-4".
* **Chart Titles:**
* (a) "Generating propaganda against targeted people."
* (b) "Advocating for terrorism."
* (c) "Generating extreme and harmful political propaganda."
* (d) "Assist with cyberattacks."
* **Bar Color:** All bars are a light red/pink color.
### Detailed Analysis or Content Details
**Chart (a): Generating propaganda against targeted people.**
* **davinci:** Approximately 10% refusal rate.
* **OPT-1.3B:** Approximately 25% refusal rate.
* **text-davinci-003:** Approximately 30% refusal rate.
* **flan-t5-xxl:** Approximately 90% refusal rate.
* **ChatGPT:** Approximately 90% refusal rate.
* **GPT-4:** Approximately 80% refusal rate.
**Chart (b): Advocating for terrorism.**
* **davinci:** Approximately 50% refusal rate.
* **OPT-1.3B:** Approximately 55% refusal rate.
* **text-davinci-003:** Approximately 60% refusal rate.
* **flan-t5-xxl:** Approximately 80% refusal rate.
* **ChatGPT:** Approximately 80% refusal rate.
* **GPT-4:** Approximately 75% refusal rate.
**Chart (c): Generating extreme and harmful political propaganda.**
* **davinci:** Approximately 40% refusal rate.
* **OPT-1.3B:** Approximately 45% refusal rate.
* **text-davinci-003:** Approximately 50% refusal rate.
* **flan-t5-xxl:** Approximately 60% refusal rate.
* **ChatGPT:** Approximately 60% refusal rate.
* **GPT-4:** Approximately 50% refusal rate.
**Chart (d): Assist with cyberattacks.**
* **davinci:** Approximately 30% refusal rate.
* **OPT-1.3B:** Approximately 40% refusal rate.
* **text-davinci-003:** Approximately 60% refusal rate.
* **flan-t5-xxl:** Approximately 80% refusal rate.
* **ChatGPT:** Approximately 85% refusal rate.
* **GPT-4:** Approximately 80% refusal rate.
### Key Observations
* Generally, refusal rates increase as the models become more advanced (moving from davinci to GPT-4).
* flan-t5-xxl and ChatGPT consistently exhibit the highest refusal rates across all prompt categories, often above 80%.
* davinci consistently has the lowest refusal rates, often below 50%.
* The prompts related to terrorism and cyberattacks elicit higher refusal rates than those related to propaganda.
* GPT-4 shows a slightly lower refusal rate than ChatGPT in some categories, but remains high overall.
### Interpretation
The data suggests that more advanced language models are more likely to refuse to answer prompts that solicit harmful or unethical responses. This is likely due to safety mechanisms and alignment training implemented in these models. The higher refusal rates for prompts related to terrorism and cyberattacks indicate that these models are more sensitive to requests that could facilitate illegal or dangerous activities. The lower refusal rate of davinci suggests that older or less sophisticated models may be more vulnerable to being exploited for malicious purposes. The consistent high refusal rates of flan-t5-xxl and ChatGPT suggest that these models have particularly strong safety guardrails. The slight decrease in refusal rate for GPT-4 compared to ChatGPT in some cases could indicate a trade-off between safety and utility, or a refinement of the safety mechanisms. Overall, the data demonstrates a positive trend towards increased safety and responsible AI development, but also highlights the ongoing need for vigilance and improvement in mitigating the risks associated with large language models.