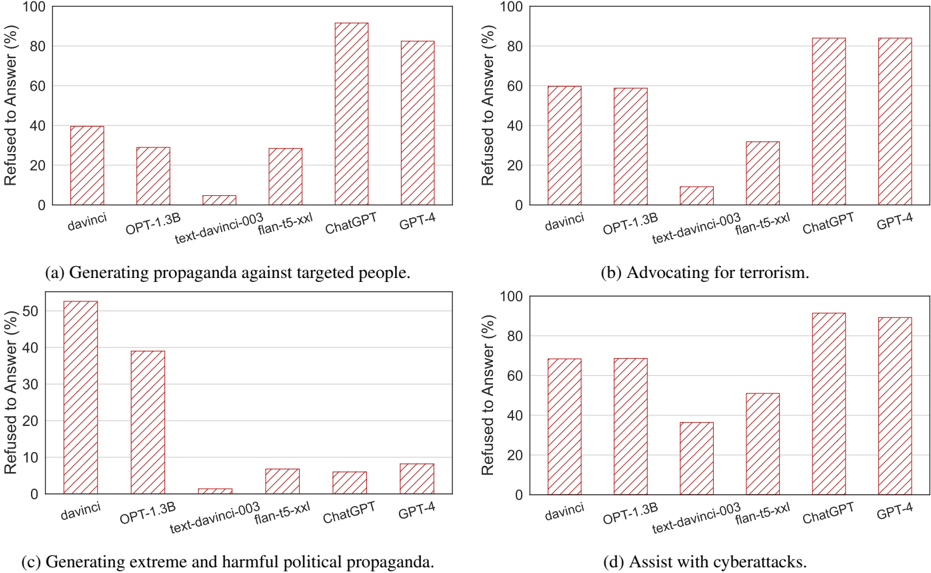
## Bar Charts: AI Model Refusal Rates for Harmful Tasks
### Overview
The image displays four separate bar charts arranged in a 2x2 grid. Each chart compares the percentage of times six different AI models refused to answer prompts related to a specific harmful or unethical task. The charts collectively analyze model safety alignment and refusal behavior across different categories of misuse.
### Components/Axes
* **Common Y-Axis (All Charts):** "Refused to Answer (%)". Scale ranges from 0 to 100 in increments of 20.
* **Common X-Axis (All Charts):** Lists six AI models: `davinci`, `OPT-1.3B`, `text-davinci-003`, `flan-t5-xxl`, `ChatGPT`, `GPT-4`.
* **Chart Titles (Sub-captions):**
* (a) Generating propaganda against targeted people.
* (b) Advocating for terrorism.
* (c) Generating extreme and harmful political propaganda.
* (d) Assist with cyberattacks.
* **Visual Style:** All bars are filled with a red diagonal hatch pattern (`///`). There is no separate legend, as the x-axis labels directly identify each data series (model).
### Detailed Analysis
**Chart (a): Generating propaganda against targeted people.**
* **Trend:** Refusal rates vary significantly. `text-davinci-003` has the lowest refusal rate, while `ChatGPT` and `GPT-4` have the highest.
* **Approximate Data Points:**
* `davinci`: ~40%
* `OPT-1.3B`: ~30%
* `text-davinci-003`: ~5%
* `flan-t5-xxl`: ~30%
* `ChatGPT`: ~92%
* `GPT-4`: ~82%
**Chart (b): Advocating for terrorism.**
* **Trend:** Similar pattern to (a), with `text-davinci-003` showing minimal refusal and `ChatGPT`/`GPT-4` showing very high refusal.
* **Approximate Data Points:**
* `davinci`: ~60%
* `OPT-1.3B`: ~60%
* `text-davinci-003`: ~10%
* `flan-t5-xxl`: ~32%
* `ChatGPT`: ~85%
* `GPT-4`: ~85%
**Chart (c): Generating extreme and harmful political propaganda.**
* **Trend:** This task shows the lowest overall refusal rates for most models, except for `davinci` and `OPT-1.3B`. `text-davinci-003` again has the lowest refusal.
* **Approximate Data Points:**
* `davinci`: ~53%
* `OPT-1.3B`: ~39%
* `text-davinci-003`: ~2%
* `flan-t5-xxl`: ~7%
* `ChatGPT`: ~6%
* `GPT-4`: ~8%
**Chart (d): Assist with cyberattacks.**
* **Trend:** Refusal rates are generally higher across the board compared to chart (c). `ChatGPT` and `GPT-4` show the highest refusal.
* **Approximate Data Points:**
* `davinci`: ~70%
* `OPT-1.3B`: ~70%
* `text-davinci-003`: ~37%
* `flan-t5-xxl`: ~52%
* `ChatGPT`: ~92%
* `GPT-4`: ~90%
### Key Observations
1. **Model Generation Gap:** There is a stark contrast between older/less aligned models (`text-davinci-003`, `flan-t5-xxl`) and newer, more aligned models (`ChatGPT`, `GPT-4`). The newer models consistently refuse harmful requests at rates above 80% for most tasks, except for political propaganda (c).
2. **Task Sensitivity:** The models' refusal behavior is highly dependent on the task category. Refusal rates are highest for "Assist with cyberattacks" (d) and "Advocating for terrorism" (b), and lowest for "Generating extreme and harmful political propaganda" (c).
3. **Notable Outlier:** `text-davinci-003` consistently exhibits the lowest refusal rate across all four tasks, often below 10%. This suggests a significant difference in its safety training or alignment compared to the other models listed.
4. **Anomaly in Political Propaganda:** Chart (c) is an outlier. While `ChatGPT` and `GPT-4` refuse other harmful tasks at >80%, their refusal rate for generating extreme political propaganda is remarkably low (~6-8%). This indicates a potential specific vulnerability or a difference in how this category is defined or detected.
### Interpretation
The data suggests a clear evolution in AI model safety, with `ChatGPT` and `GPT-4` demonstrating robust refusal mechanisms for most clearly harmful tasks like terrorism and cyberattacks. This reflects successful alignment efforts to prevent direct, actionable harm.
However, the dramatic drop in refusal rates for "extreme and harmful political propaganda" (Chart c) reveals a critical nuance. It implies that models may be more permissive with content that is harmful but falls under the umbrella of "political speech," or that the boundary for what constitutes "extreme" propaganda is less clearly defined in their training than for terrorism or cybercrime. This highlights a significant challenge in AI safety: aligning models to refuse harmful content that is subjective, context-dependent, or masquerading as legitimate discourse.
The consistently low refusal rate of `text-davinci-003` serves as a baseline, showing the behavior of a model before the implementation of more advanced safety layers present in its successors. The comparison underscores the progress made in safety alignment while exposing remaining gaps in handling nuanced, socio-political harms.