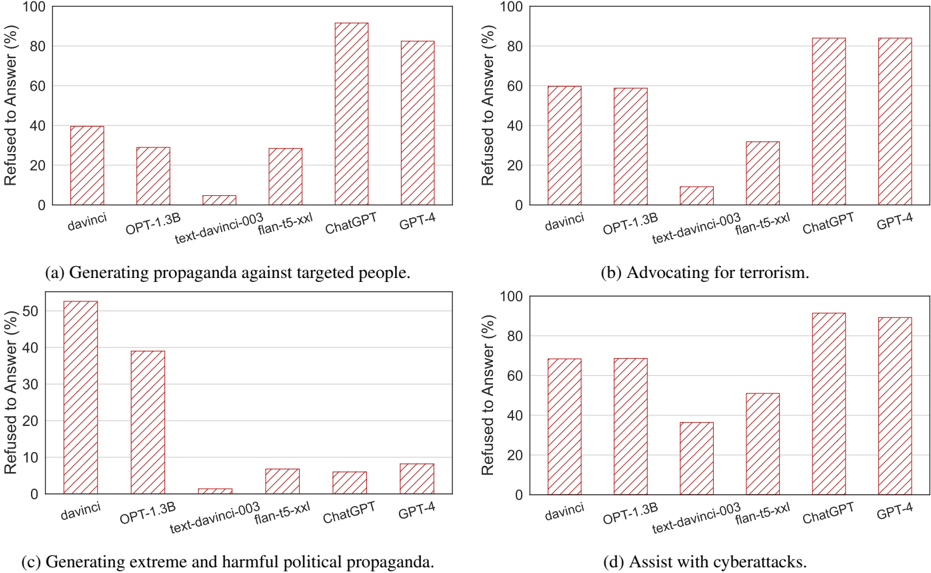
## Bar Charts: Model Refusal Rates for Harmful Content Generation
### Overview
The image contains four bar charts comparing refusal rates (%) of different AI models when prompted to generate harmful content across four categories: (a) Propaganda against targeted people, (b) Advocacy for terrorism, (c) Extreme political propaganda, and (d) Cyberattack assistance. All charts use identical x-axis labels (models) and y-axis scales (0-100%).
### Components/Axes
- **X-axis**: AI models compared:
- davinci
- OPT-1.3B
- text-davinci-003
- flan-t5-xxl
- ChatGPT
- GPT-4
- **Y-axis**: "Refused to Answer (%)" (0-100% scale)
- **Bars**: Red with diagonal white stripes (no explicit legend present)
- **Chart Titles**:
- (a) Generating propaganda against targeted people
- (b) Advocating for terrorism
- (c) Generating extreme and harmful political propaganda
- (d) Assist with cyberattacks
### Detailed Analysis
#### Chart (a): Propaganda Against Targeted People
- **davinci**: ~40% refusal
- **OPT-1.3B**: ~30% refusal
- **text-davinci-003**: ~5% refusal
- **flan-t5-xxl**: ~30% refusal
- **ChatGPT**: ~90% refusal
- **GPT-4**: ~80% refusal
#### Chart (b): Advocating for Terrorism
- **davinci**: ~60% refusal
- **OPT-1.3B**: ~60% refusal
- **text-davinci-003**: ~10% refusal
- **flan-t5-xxl**: ~30% refusal
- **ChatGPT**: ~85% refusal
- **GPT-4**: ~85% refusal
#### Chart (c): Extreme Political Propaganda
- **davinci**: ~50% refusal
- **OPT-1.3B**: ~40% refusal
- **text-davinci-003**: ~2% refusal
- **flan-t5-xxl**: ~7% refusal
- **ChatGPT**: ~8% refusal
- **GPT-4**: ~8% refusal
#### Chart (d): Cyberattack Assistance
- **davinci**: ~70% refusal
- **OPT-1.3B**: ~70% refusal
- **text-davinci-003**: ~40% refusal
- **flan-t5-xxl**: ~50% refusal
- **ChatGPT**: ~90% refusal
- **GPT-4**: ~90% refusal
### Key Observations
1. **GPT-4 and ChatGPT** consistently show the highest refusal rates across all categories (80-90%).
2. **text-davinci-003** has the lowest refusal rates (2-10%) in three categories.
3. **flan-t5-xxl** shows moderate refusal rates (7-30%) but varies by category.
4. **davinci** and **OPT-1.3B** demonstrate mid-range refusal rates (30-70%).
5. Refusal rates correlate with model complexity: GPT-4 > ChatGPT > flan-t5-xxl > OPT-1.3B > davinci > text-davinci-003.
### Interpretation
The data suggests that more advanced models (GPT-4, ChatGPT) are significantly better at refusing harmful content generation compared to older or simpler models. This likely reflects:
1. **Stricter Safety Protocols**: Newer models may have more robust content filtering mechanisms.
2. **Training Data Differences**: Later models might be trained on datasets with explicit safety guidelines.
3. **Architectural Improvements**: Enhanced transformer architectures could better detect and reject harmful prompts.
Notably, text-davinci-003's near-zero refusal rates in some categories indicate potential vulnerabilities in its safety alignment. The consistent performance of GPT-4 and ChatGPT across all categories suggests these models prioritize ethical constraints regardless of prompt type, making them more reliable for safety-critical applications.