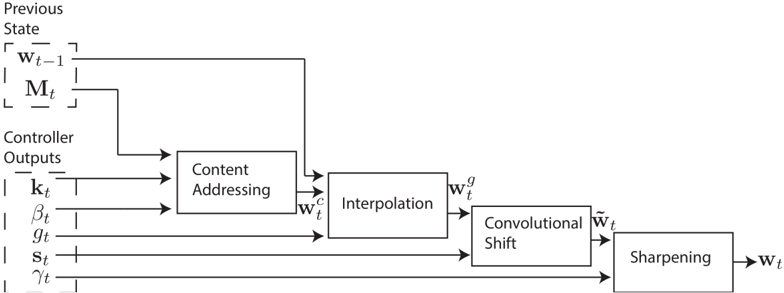
## Diagram: Memory Addressing and Update Process
### Overview
The image displays a technical block diagram illustrating a sequential process for updating a weight or state vector, denoted as **w_t**. The process takes a previous state and a set of controller outputs as inputs and passes them through four distinct computational stages: Content Addressing, Interpolation, Convolutional Shift, and Sharpening. The diagram is presented in a clean, black-and-white schematic style with labeled blocks and directional arrows indicating data flow.
### Components/Axes
The diagram is organized into three main vertical sections from left to right:
1. **Inputs (Left Side):**
* **Previous State:** A dashed box containing two elements:
* `w_{t-1}` (Previous weight/state vector)
* `M_t` (Memory matrix at time t)
* **Controller Outputs:** A dashed box containing five scalar or vector outputs:
* `k_t` (Key vector)
* `β_t` (Beta, likely a strength or temperature parameter)
* `g_t` (Gamma, likely an interpolation gate)
* `s_t` (Shift filter or vector)
* `γ_t` (Gamma, likely a sharpening parameter)
2. **Processing Blocks (Center):**
* **Content Addressing:** Receives `w_{t-1}`, `M_t`, `k_t`, and `β_t`. Outputs `w_t^c`.
* **Interpolation:** Receives `w_t^c` and `g_t`. Outputs `w_t^g`.
* **Convolutional Shift:** Receives `w_t^g` and `s_t`. Outputs `w̃_t` (w-tilde).
* **Sharpening:** Receives `w̃_t` and `γ_t`. Outputs the final `w_t`.
3. **Output (Right Side):**
* The final output is the updated vector `w_t`.
### Detailed Analysis
The process flow is strictly sequential and can be traced as follows:
1. **Content Addressing Stage:**
* **Inputs:** The previous weight vector `w_{t-1}` and the memory matrix `M_t` from the Previous State block, along with the controller outputs `k_t` and `β_t`.
* **Operation:** This block likely performs a content-based lookup or attention mechanism using the key `k_t` and strength `β_t` to produce an addressed weight vector `w_t^c`.
* **Output:** `w_t^c` (Content-addressed weights).
2. **Interpolation Stage:**
* **Inputs:** The output from the previous stage, `w_t^c`, and the controller output `g_t`.
* **Operation:** This block blends or gates the content-addressed weights `w_t^c` with the previous state `w_{t-1}` (implied by the connection from the top) using the parameter `g_t`. The notation suggests a convex combination or gated update.
* **Output:** `w_t^g` (Interpolated weights).
3. **Convolutional Shift Stage:**
* **Inputs:** The interpolated weights `w_t^g` and the controller output `s_t`.
* **Operation:** This block applies a convolutional shift operation, likely a circular shift or permutation, to the weight vector as defined by `s_t`.
* **Output:** `w̃_t` (Shifted weights).
4. **Sharpening Stage:**
* **Inputs:** The shifted weights `w̃_t` and the controller output `γ_t`.
* **Operation:** This final block applies a sharpening function, often a power operation (e.g., raising each element to the power of `γ_t`), to make the weight distribution more peaked or discrete.
* **Output:** The final updated weight vector `w_t`.
### Key Observations
* **Modular Design:** The process is decomposed into four clear, independent modules, each performing a specific transformation.
* **Parameter Flow:** Each processing block (except the first) receives a dedicated control parameter (`g_t`, `s_t`, `γ_t`) directly from the Controller Outputs, indicating fine-grained, step-wise control over the update process.
* **State Preservation:** The connection from `w_{t-1}` directly to the Interpolation block (bypassing Content Addressing) suggests a residual or skip connection, allowing the model to retain information from the previous timestep.
* **Notation Consistency:** The use of superscripts (`c`, `g`) and diacritics (`~`) clearly denotes the intermediate state of the weight vector after each processing stage.
### Interpretation
This diagram almost certainly depicts the **external memory update mechanism** from a differentiable neural computer (DNC) or a similar memory-augmented neural network architecture. The process is a sophisticated method for writing to a memory matrix (`M_t`) by first reading from it via content-based addressing and then applying a series of transformations to refine the write weights (`w_t`).
* **Purpose:** The goal is to compute a precise, sparse, and location-aware weight vector `w_t` that will be used to modify the memory `M_t`. This allows the network to store new information in specific, content-related locations while maintaining temporal coherence.
* **Relationship of Elements:** The Controller Outputs (`k_t`, `β_t`, `g_t`, `s_t`, `γ_t`) are the "knobs" that a neural network controller (e.g., an RNN) learns to manipulate to control memory access. Each stage addresses a different aspect of memory writing: what to write (Content Addressing), how much to blend with old knowledge (Interpolation), where to write it relative to previous writes (Convolutional Shift), and how decisively to write it (Sharpening).
* **Anomalies/Notables:** The presence of two distinct parameters named `γ_t` (one in Controller Outputs, used in Sharpening) is notable. This is standard in DNC literature, where `γ` is typically used for sharpening. The diagram's clarity in separating the "read" path (Content Addressing) from the "write" path (the subsequent transformations) is a key architectural insight. The entire process ensures that memory updates are both content-addressable and location-sensitive, enabling complex reasoning and recall tasks.