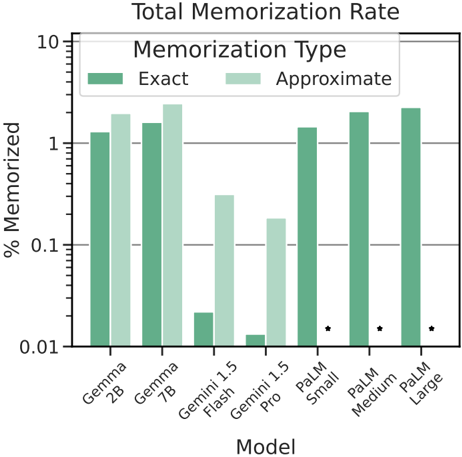
## Chart Type: Bar Chart
### Overview
The image is a bar chart comparing the total memorization rate of different models. The y-axis represents the percentage of memorization on a logarithmic scale, ranging from 0.01% to 10%. The x-axis lists the models being compared: Gemma 2B, Gemma 7B, Gemini 1.5 Flash, Gemini 1.5 Pro, PaLM Small, PaLM Medium, and PaLM Large. The chart compares "Exact" and "Approximate" memorization types for each model, using green and light green bars respectively.
### Components/Axes
* **Title:** Total Memorization Rate
* **X-Axis Title:** Model
* **X-Axis Labels:** Gemma 2B, Gemma 7B, Gemini 1.5 Flash, Gemini 1.5 Pro, PaLM Small, PaLM Medium, PaLM Large
* **Y-Axis Title:** % Memorized
* **Y-Axis Scale:** Logarithmic, ranging from 0.01 to 10
* **Y-Axis Markers:** 0.01, 0.1, 1, 10
* **Legend:** Located at the top-left of the chart.
* **Exact:** Represented by a green bar.
* **Approximate:** Represented by a light green bar.
### Detailed Analysis
* **Gemma 2B:**
* Exact: Approximately 1.3%
* Approximate: Approximately 2.0%
* **Gemma 7B:**
* Exact: Approximately 1.6%
* Approximate: Approximately 2.5%
* **Gemini 1.5 Flash:**
* Exact: Approximately 0.02%
* Approximate: Approximately 0.3%
* **Gemini 1.5 Pro:**
* Exact: Approximately 0.01%
* Approximate: Approximately 0.2%
* **PaLM Small:**
* Exact: Approximately 1.4%
* Approximate: No data available. Indicated by a star.
* **PaLM Medium:**
* Exact: Approximately 2.0%
* Approximate: No data available. Indicated by a star.
* **PaLM Large:**
* Exact: Approximately 2.2%
* Approximate: No data available. Indicated by a star.
### Key Observations
* For Gemma models, approximate memorization rates are higher than exact memorization rates.
* For Gemini 1.5 models, both exact and approximate memorization rates are significantly lower than Gemma and PaLM models.
* PaLM models show a trend of increasing exact memorization rate as the model size increases (Small to Large).
* Approximate memorization data is missing for all PaLM models, indicated by stars.
### Interpretation
The chart compares the memorization capabilities of different language models, distinguishing between exact and approximate memorization. The Gemma models show relatively high memorization rates for both exact and approximate types. The Gemini 1.5 models have significantly lower memorization rates, suggesting a different architecture or training approach. The PaLM models show a trend of increasing exact memorization with model size, but lack data for approximate memorization. The missing data for approximate memorization in PaLM models could indicate a limitation or specific design choice in how these models handle approximate memorization tasks.