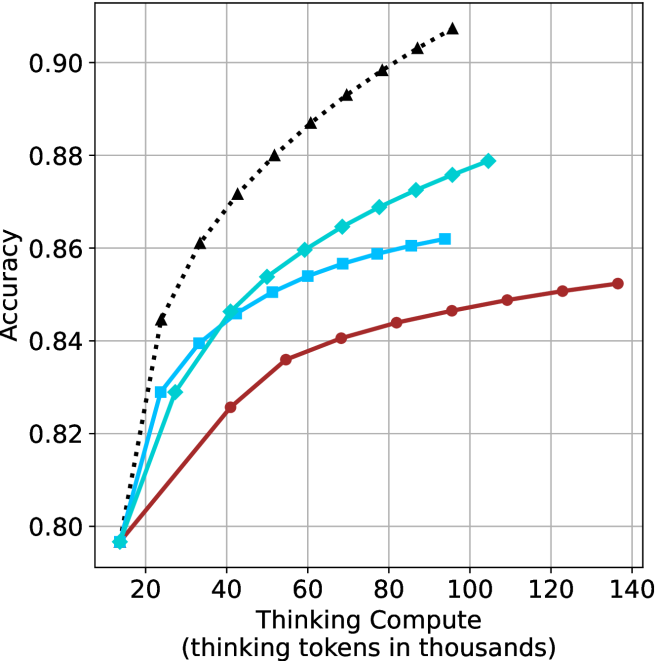
## Line Graph: Accuracy vs. Thinking Compute (Thinking Tokens in Thousands)
### Overview
The graph illustrates the relationship between computational resource allocation (measured in thinking tokens) and model accuracy across three configurations: baseline thinking compute, thinking compute with prompting, and thinking compute with prompting plus chain-of-thought reasoning. Three distinct data series are plotted against a logarithmic-like scale of compute resources.
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Range: 20k to 140k tokens
- Tick intervals: 20k increments
- **Y-axis**: "Accuracy"
- Range: 0.80 to 0.90
- Tick intervals: 0.02 increments
- **Legend**: Top-right corner
- Labels:
1. "Thinking Compute" (black dashed line with triangles)
2. "Thinking Compute + Prompting" (blue solid line with squares)
3. "Thinking Compute + Prompting + Chain-of-Thought" (red solid line with circles)
### Detailed Analysis
1. **Thinking Compute (Black Dashed Line)**
- Starts at (20k, 0.80)
- Steadily increases to (140k, 0.90)
- Key points:
- 40k tokens: 0.84
- 60k tokens: 0.86
- 80k tokens: 0.88
- 100k tokens: 0.89
- 120k tokens: 0.90
- 140k tokens: 0.90
2. **Thinking Compute + Prompting (Blue Solid Line)**
- Starts at (20k, 0.80)
- Peaks at (80k, 0.88)
- Declines slightly to (140k, 0.86)
- Key points:
- 40k tokens: 0.84
- 60k tokens: 0.85
- 80k tokens: 0.88
- 100k tokens: 0.87
- 120k tokens: 0.86
- 140k tokens: 0.86
3. **Thinking Compute + Prompting + Chain-of-Thought (Red Solid Line)**
- Starts at (20k, 0.80)
- Gradual increase to (140k, 0.85)
- Key points:
- 40k tokens: 0.83
- 60k tokens: 0.84
- 80k tokens: 0.85
- 100k tokens: 0.85
- 120k tokens: 0.85
- 140k tokens: 0.85
### Key Observations
- **Diminishing Returns**: The blue line (prompting) shows a sharp peak at 80k tokens, followed by a decline, suggesting prompting alone becomes less effective at higher compute scales.
- **Consistent Gains**: The red line (chain-of-thought) demonstrates stable, incremental improvements across all compute levels, outperforming the blue line at 100k+ tokens.
- **Baseline Scaling**: The black dashed line (baseline compute) shows linear scaling but plateaus at 0.90 accuracy beyond 100k tokens.
### Interpretation
The data suggests that **chain-of-thought reasoning** provides the most robust accuracy improvements across compute scales, particularly at higher resource levels (100k+ tokens), where prompting alone underperforms. This implies that:
1. **Method Synergy**: Combining prompting with chain-of-thought reasoning mitigates the diminishing returns observed in prompting-only configurations.
2. **Compute Efficiency**: At lower compute levels (<80k tokens), prompting significantly boosts accuracy, but its benefits plateau or reverse at higher scales.
3. **Scalability Trade-offs**: While baseline compute scales linearly, method enhancements (prompting + chain-of-thought) offer non-linear gains, making them more cost-effective for high-accuracy applications.
The graph highlights the importance of architectural improvements (e.g., chain-of-thought) over raw compute scaling alone for optimizing model performance.