\n
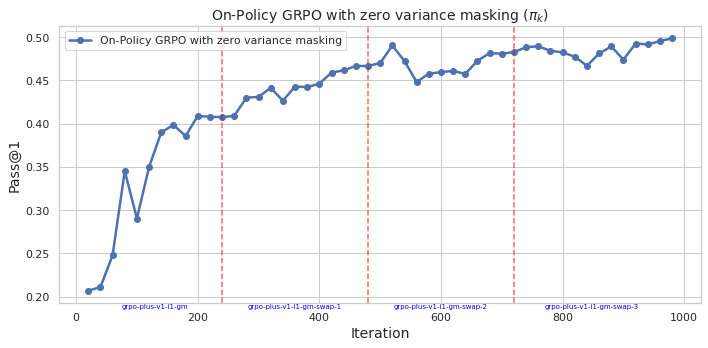
## Line Chart: On-Policy GRPO with zero variance masking
### Overview
This image presents a line chart illustrating the performance of an "On-Policy GRPO with zero variance masking" algorithm over iterations. The chart plots "Pass@1" on the y-axis against "Iteration" on the x-axis. Vertical dashed red lines mark specific iteration points with labels indicating algorithm versions or stages.
### Components/Axes
* **Title:** "On-Policy GRPO with zero variance masking (πk)" - positioned at the top-center of the chart.
* **X-axis:** "Iteration" - ranging from 0 to 1000, with tick marks at intervals of 100.
* **Y-axis:** "Pass@1" - ranging from 0.20 to 0.50, with tick marks at intervals of 0.05.
* **Data Series:** A single line representing "On-Policy GRPO with zero variance masking" - colored in dark blue.
* **Legend:** Located in the top-left corner, labeling the data series.
* **Vertical Dashed Lines:** Four vertical dashed red lines are present at approximately iterations 200, 400, 600, and 800.
* **Labels on X-axis:** "grpo-plus-v1-1-gm", "grpo-plus-v1-1-gm-swap-1", "grpo-plus-v1-1-gm-swap-2", "grpo-plus-v1-1-gm-swap-3"
### Detailed Analysis
The blue line representing "On-Policy GRPO with zero variance masking" shows a generally increasing trend, with some fluctuations.
* **Iteration 0:** Pass@1 is approximately 0.21.
* **Iteration 100:** Pass@1 is approximately 0.36, with a dip to around 0.32 at iteration 50.
* **Iteration 200:** Pass@1 is approximately 0.41. The first vertical dashed red line is positioned here, labeled "grpo-plus-v1-1-gm".
* **Iteration 400:** Pass@1 is approximately 0.45. The second vertical dashed red line is positioned here, labeled "grpo-plus-v1-1-gm-swap-1".
* **Iteration 600:** Pass@1 is approximately 0.47. The third vertical dashed red line is positioned here, labeled "grpo-plus-v1-1-gm-swap-2".
* **Iteration 800:** Pass@1 is approximately 0.46. The fourth vertical dashed red line is positioned here, labeled "grpo-plus-v1-1-gm-swap-3".
* **Iteration 1000:** Pass@1 is approximately 0.48.
* The line reaches a peak of approximately 0.49 around iteration 550.
* There is a slight decrease in Pass@1 between iterations 600 and 700, dropping to around 0.45.
* The line fluctuates between approximately 0.46 and 0.48 from iteration 700 to 1000.
### Key Observations
* The algorithm demonstrates a clear improvement in Pass@1 as the number of iterations increases, although the improvement plateaus after iteration 600.
* The vertical dashed lines indicate points where the algorithm or its configuration was modified (e.g., "swap-1", "swap-2", "swap-3"). These modifications do not consistently lead to immediate improvements in Pass@1.
* The initial learning phase (iterations 0-200) shows a rapid increase in Pass@1.
* The fluctuations in the line after iteration 600 suggest that the algorithm may be approaching a local optimum or experiencing some instability.
### Interpretation
The chart suggests that the "On-Policy GRPO with zero variance masking" algorithm is effective in improving performance (as measured by Pass@1) over iterations. The algorithm shows significant gains in the initial stages of training, but the rate of improvement slows down as it converges. The vertical dashed lines, representing changes to the algorithm, provide insights into the impact of different configurations. The fact that the algorithm doesn't consistently improve with each modification suggests that the optimal configuration may be complex and require careful tuning. The fluctuations in the later stages of training could indicate the need for further optimization or regularization techniques to prevent overfitting or instability. The algorithm appears to be converging towards a Pass@1 value of approximately 0.48, which may represent its maximum achievable performance under the given conditions.