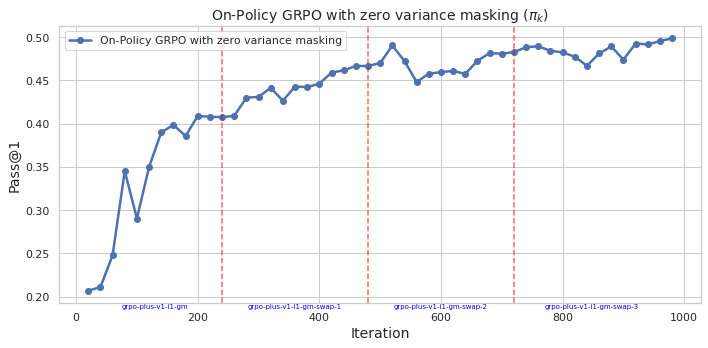
## Line Chart: On-Policy GRPO with zero variance masking (π_k)
### Overview
The chart depicts the performance of an on-policy GRPO algorithm with zero variance masking across 1,000 iterations. The metric measured is "Pass@1" (y-axis), showing improvement over time with notable fluctuations and stabilization phases. Red dashed vertical lines mark specific iteration points labeled as "gpo-plus-v1-1-gm-swap-1" through "gpo-plus-v1-1-gm-swap-3".
### Components/Axes
- **X-axis (Iteration)**: Labeled "iteration" with values from 0 to 1,000. Red dashed vertical lines at:
- 200 ("gpo-plus-v1-1-gm-swap-1")
- 400 ("gpo-plus-v1-1-gm-swap-2")
- 600 ("gpo-plus-v1-1-gm-swap-3")
- 800 ("gpo-plus-v1-1-gm-swap-4")
- **Y-axis (Pass@1)**: Labeled "Pass@1" with values from 0.20 to 0.50 in increments of 0.05.
- **Legend**: Located in the top-right corner, matching the blue line to "On-Policy GRPO with zero variance masking".
- **Line**: Blue line representing the "Pass@1" metric over iterations.
### Detailed Analysis
- **Initial Phase (0–200 iterations)**:
- Starts at ~0.20 (iteration 0).
- Sharp rise to ~0.35 at iteration 50.
- Dip to ~0.29 at iteration 100.
- Gradual increase to ~0.40 by iteration 200.
- **First Swap (200–400 iterations)**:
- Slight dip to ~0.39 at iteration 250.
- Steady climb to ~0.44 by iteration 400.
- **Second Swap (400–600 iterations)**:
- Peak at ~0.49 at iteration 500.
- Minor fluctuations between ~0.44–0.47.
- **Third Swap (600–800 iterations)**:
- Stabilization around ~0.46–0.48.
- Slight dip to ~0.45 at iteration 700.
- **Final Phase (800–1,000 iterations)**:
- Consistent performance above ~0.47.
- Final value ~0.50 at iteration 1,000.
### Key Observations
1. **Initial Volatility**: Sharp early fluctuations (0–100 iterations) followed by stabilization.
2. **Swap Correlation**: Performance improvements align with "gm-swap" events, suggesting parameter/model adjustments.
3. **Stabilization**: Post-600 iterations, performance stabilizes near 0.47–0.50, indicating convergence.
4. **Zero Variance Masking**: The technique appears effective in maintaining consistent performance after initial training.
### Interpretation
The data demonstrates that the on-policy GRPO algorithm with zero variance masking achieves robust performance gains over time, particularly after iterative "gm-swap" events. The initial volatility suggests sensitivity to early training dynamics, while later stabilization indicates effective convergence. The "gm-swap" events likely represent critical updates (e.g., gradient masking adjustments) that enhance model robustness. The final Pass@1 score of ~0.50 implies strong task-specific accuracy, validating the efficacy of zero variance masking in mitigating performance variance during training.