## Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Qwen2.5-Math-7B)
### Overview
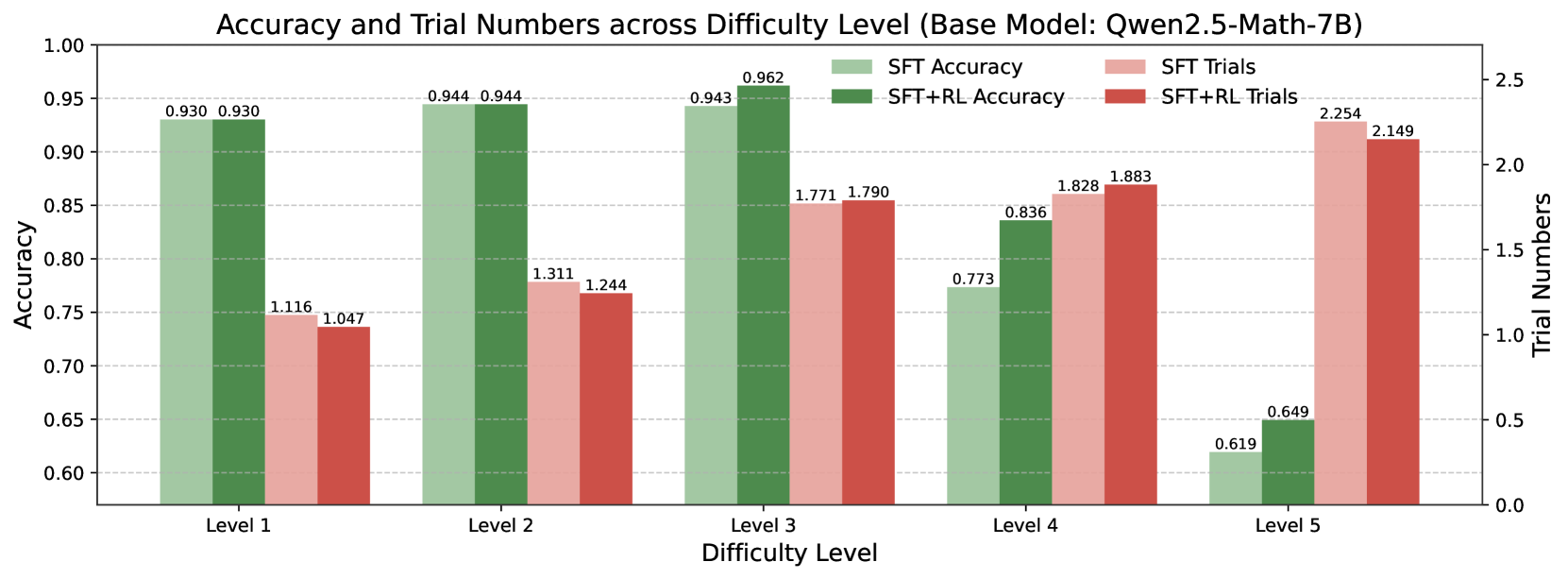
The image is a bar chart comparing the accuracy and trial numbers of two models, SFT and SFT+RL, across five difficulty levels. The chart displays accuracy on the left y-axis and trial numbers on the right y-axis. The x-axis represents the difficulty levels.
### Components/Axes
* **Title:** Accuracy and Trial Numbers across Difficulty Level (Base Model: Qwen2.5-Math-7B)
* **X-axis:** Difficulty Level, with categories: Level 1, Level 2, Level 3, Level 4, Level 5
* **Left Y-axis:** Accuracy, ranging from 0.60 to 1.00 in increments of 0.05.
* **Right Y-axis:** Trial Numbers, ranging from 0.0 to 2.5 in increments of 0.5.
* **Legend:** Located at the top-right of the chart.
* SFT Accuracy (light green)
* SFT+RL Accuracy (dark green)
* SFT Trials (light red)
* SFT+RL Trials (dark red)
### Detailed Analysis
* **Level 1:**
* SFT Accuracy: 0.930
* SFT+RL Accuracy: 0.930
* SFT Trials: 1.116
* SFT+RL Trials: 1.047
* **Level 2:**
* SFT Accuracy: 0.944
* SFT+RL Accuracy: 0.944
* SFT Trials: 1.311
* SFT+RL Trials: 1.244
* **Level 3:**
* SFT Accuracy: 0.943
* SFT+RL Accuracy: 0.962
* SFT Trials: 1.771
* SFT+RL Trials: 1.790
* **Level 4:**
* SFT Accuracy: 0.773
* SFT+RL Accuracy: 0.836
* SFT Trials: 1.828
* SFT+RL Trials: 1.883
* **Level 5:**
* SFT Accuracy: 0.619
* SFT+RL Accuracy: 0.649
* SFT Trials: 2.254
* SFT+RL Trials: 2.149
### Key Observations
* **Accuracy:** Both SFT and SFT+RL models show high accuracy at Levels 1, 2, and 3, with accuracy decreasing significantly at Levels 4 and 5. SFT+RL accuracy is slightly higher than SFT accuracy at levels 3, 4, and 5.
* **Trial Numbers:** The number of trials generally increases with difficulty level. Levels 4 and 5 have the highest trial numbers for both SFT and SFT+RL.
### Interpretation
The chart suggests that the base model (Qwen2.5-Math-7B) performs well on easier difficulty levels (1-3) but struggles with more difficult levels (4-5), as indicated by the lower accuracy and higher number of trials required. The addition of Reinforcement Learning (RL) in the SFT+RL model seems to provide a slight improvement in accuracy, particularly at higher difficulty levels, but does not drastically change the overall trend. The increase in trial numbers at higher difficulty levels indicates that the model requires more attempts to achieve a correct answer, reflecting the increased complexity of the problems.