## Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Qwen2.5-Math-7B)
### Overview
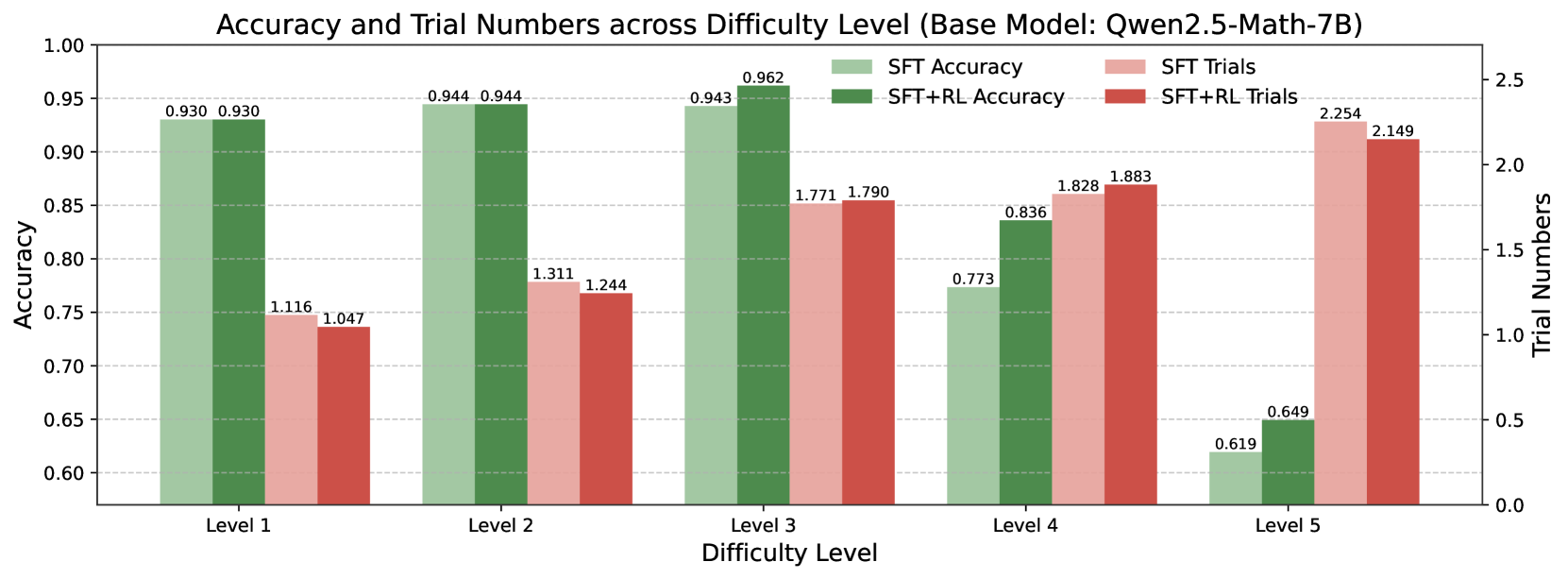
The chart compares the accuracy and trial numbers of two model configurations (SFT and SFT+RL) across five difficulty levels (1–5). Accuracy is measured on a 0.6–1.0 scale (left y-axis), while trial numbers are measured on a 0–2.5 scale (right y-axis). The legend distinguishes SFT (light green/light pink) and SFT+RL (dark green/dark red) configurations.
### Components/Axes
- **X-axis**: Difficulty Levels (Level 1 to Level 5, labeled sequentially).
- **Left Y-axis**: Accuracy (0.6–1.0, increments of 0.05).
- **Right Y-axis**: Trial Numbers (0–2.5, increments of 0.5).
- **Legend**: Located on the right, with four color-coded categories:
- Light green: SFT Accuracy
- Dark green: SFT+RL Accuracy
- Light pink: SFT Trials
- Dark red: SFT+RL Trials
### Detailed Analysis
#### Difficulty Level 1
- **Accuracy**:
- SFT Accuracy: 0.930 (light green)
- SFT+RL Accuracy: 0.930 (dark green)
- **Trials**:
- SFT Trials: 1.116 (light pink)
- SFT+RL Trials: 1.047 (dark red)
#### Difficulty Level 2
- **Accuracy**:
- SFT Accuracy: 0.944 (light green)
- SFT+RL Accuracy: 0.944 (dark green)
- **Trials**:
- SFT Trials: 1.311 (light pink)
- SFT+RL Trials: 1.244 (dark red)
#### Difficulty Level 3
- **Accuracy**:
- SFT Accuracy: 0.943 (light green)
- SFT+RL Accuracy: 0.962 (dark green)
- **Trials**:
- SFT Trials: 1.771 (light pink)
- SFT+RL Trials: 1.790 (dark red)
#### Difficulty Level 4
- **Accuracy**:
- SFT Accuracy: 0.773 (light green)
- SFT+RL Accuracy: 0.836 (dark green)
- **Trials**:
- SFT Trials: 1.828 (light pink)
- SFT+RL Trials: 1.883 (dark red)
#### Difficulty Level 5
- **Accuracy**:
- SFT Accuracy: 0.619 (light green)
- SFT+RL Accuracy: 0.649 (dark green)
- **Trials**:
- SFT Trials: 2.254 (light pink)
- SFT+RL Trials: 2.149 (dark red)
### Key Observations
1. **Accuracy Trends**:
- SFT+RL consistently outperforms SFT in accuracy across all levels except Level 1 (where they are equal).
- Accuracy declines sharply for SFT at Level 4 (0.773) and Level 5 (0.619), while SFT+RL maintains higher performance (0.836 and 0.649, respectively).
2. **Trial Number Trends**:
- Trial numbers increase with difficulty for both configurations, peaking at Level 5 (SFT: 2.254, SFT+RL: 2.149).
- SFT requires more trials than SFT+RL in Levels 1, 4, and 5, but fewer in Levels 2 and 3.
### Interpretation
The data demonstrates that **reinforcement learning (RL) improves accuracy**, particularly in higher difficulty levels where SFT struggles. While SFT+RL requires fewer trials in most cases, the exception at Level 5 suggests RL may not always reduce trial numbers for extremely hard problems. The divergence in accuracy at Level 5 highlights the limitations of both configurations for highly complex tasks. The trial number trends indicate that difficulty correlates with increased computational effort, but RL mitigates this burden in most scenarios.