## Diagram: Neural Network and Chip Implementation with Performance Comparison
### Overview
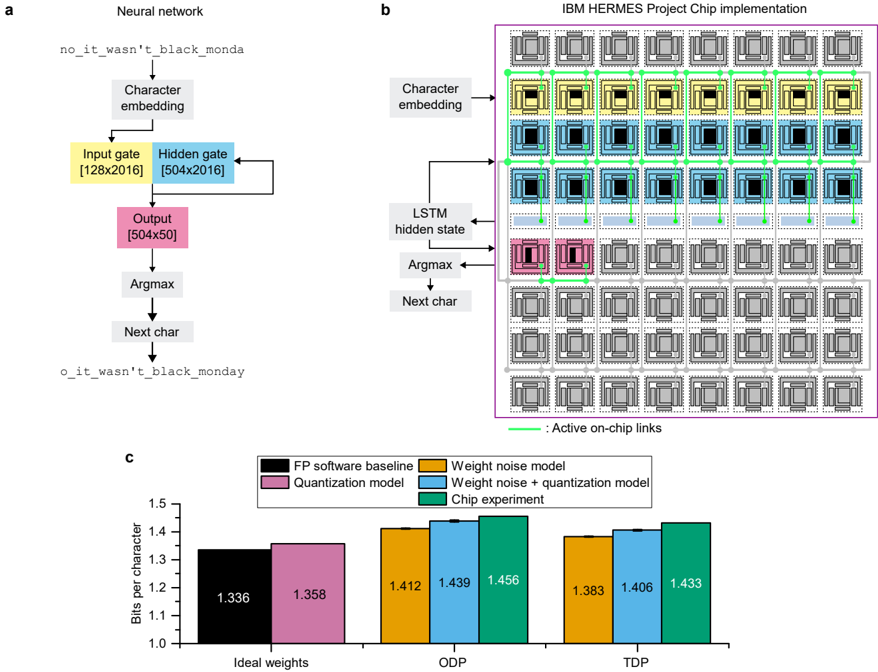
The image presents a comparison between a neural network architecture and its implementation on the IBM HERMES chip. It consists of three parts: (a) a schematic of a neural network for character prediction, (b) a visualization of the chip implementation of the same network, and (c) a bar chart comparing the performance of different models in terms of bits per character.
### Components/Axes
**Part a: Neural Network**
* **Input:** "no_it_wasn't_black_monday"
* **Layers:** Character embedding, Input gate [128x2016], Hidden gate [504x2016], Output [504x50], Argmax, Next char
* **Output:** "o_it_wasn't_black_monday"
**Part b: Chip Implementation**
* **Layers:** Character embedding, LSTM hidden state, Argmax, Next char
* **Annotation:** "Active on-chip links"
**Part c: Performance Comparison (Bar Chart)**
* **X-axis:** Ideal weights, ODP, TDP
* **Y-axis:** Bits per character (Scale: 1.0 to 1.6)
* **Legend:**
* FP software baseline (Black)
* Quantization model (Dark Grey)
* Weight noise model (Purple)
* Weight noise + quantization model (Teal)
* Chip experiment (Light Blue)
### Detailed Analysis or Content Details
**Part a: Neural Network**
The diagram shows a sequential flow of information. The input string "no_it_wasn't_black_monday" is processed through a character embedding layer, followed by input and hidden gates with specified dimensions (128x2016 and 504x2016 respectively). The output layer has dimensions 504x50. An Argmax function selects the next character, resulting in the output string "o_it_wasn't_black_monday".
**Part b: Chip Implementation**
The chip implementation visualizes a grid-like structure with colored boxes representing different components. The "Active on-chip links" are indicated by lines connecting the boxes. The layers are labeled as Character embedding, LSTM hidden state, Argmax, and Next char, mirroring the neural network schematic. The chip appears to have a highly interconnected structure.
**Part c: Performance Comparison (Bar Chart)**
* **Ideal Weights:**
* FP software baseline: ~1.336 bits/character
* Quantization model: ~1.358 bits/character
* Weight noise model: ~1.412 bits/character
* Weight noise + quantization model: ~1.439 bits/character
* Chip experiment: ~1.456 bits/character
* **ODP:**
* FP software baseline: ~1.412 bits/character
* Quantization model: ~1.439 bits/character
* Weight noise model: ~1.456 bits/character
* Weight noise + quantization model: ~1.439 bits/character
* Chip experiment: ~1.383 bits/character
* **TDP:**
* FP software baseline: ~1.406 bits/character
* Quantization model: ~1.433 bits/character
* Weight noise model: ~1.406 bits/character
* Weight noise + quantization model: ~1.433 bits/character
* Chip experiment: ~1.383 bits/character
The FP software baseline consistently shows the lowest bits per character across all conditions. The chip experiment performs well, sometimes outperforming the software baseline, particularly in ODP and TDP.
### Key Observations
* The chip experiment shows a performance close to or better than the software baseline in ODP and TDP.
* Adding weight noise and quantization generally increases the bits per character, indicating a potential loss of accuracy.
* The performance difference between the models is relatively small, suggesting that the implemented techniques have a moderate impact.
### Interpretation
The image demonstrates the implementation of a neural network for character prediction on a specialized chip (IBM HERMES). The bar chart compares the performance of different models, including a floating-point software baseline, quantized models, and models incorporating weight noise. The results suggest that the chip implementation can achieve performance comparable to or better than the software baseline, particularly when optimized for specific power and performance conditions (ODP and TDP). The increase in bits per character with weight noise and quantization indicates a trade-off between model complexity, accuracy, and resource usage. The visualization of the chip implementation highlights the complex interconnection of components required to execute the neural network efficiently. The data suggests that the chip is successfully implementing the neural network and achieving competitive performance. The slight performance gains observed in the chip experiment could be attributed to hardware acceleration and optimized data flow.