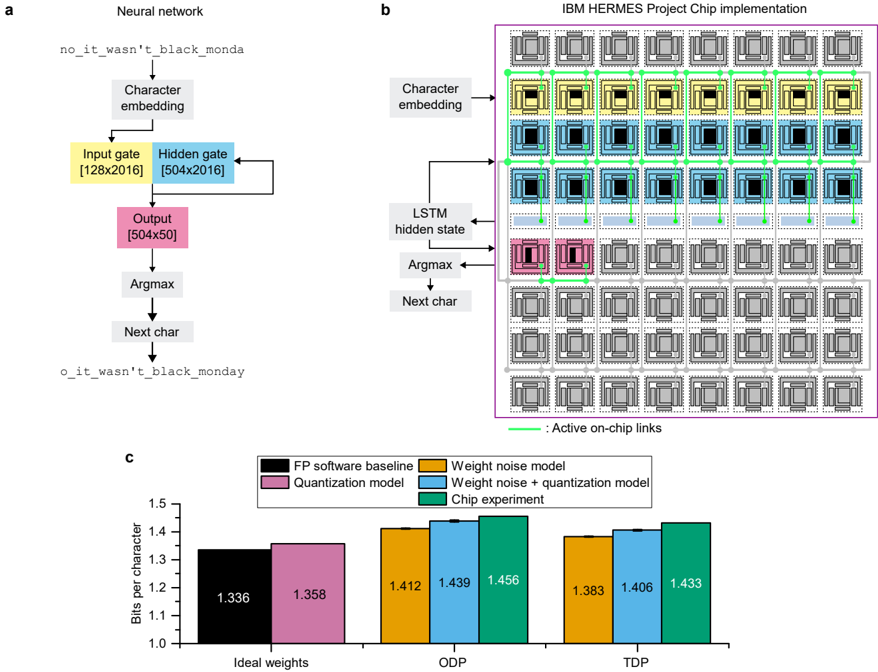
## Chart/Diagram Type: Technical Architecture and Performance Comparison
### Overview
The image contains three components:
1. **Neural Network Architecture (a)**: A character-level language model processing input text.
2. **IBM HERMES Project Chip Implementation (b)**: A hardware layout for executing the neural network.
3. **Bar Chart (c)**: Comparison of bits per character across different model configurations.
### Components/Axes
#### Neural Network (a)
- **Input**: `no_it_wasn't_black_monda`
- **Output**: `o_it_wasn't_black_monday`
- **Layers**:
- **Input Gate**: [128x2016]
- **Hidden Gate**: [504x2016]
- **Output**: [504x50]
- **Operations**:
- Character embedding → Input gate → Hidden gate → Output → Argmax → Next char
#### IBM HERMES Project Chip (b)
- **Grid Layout**:
- **Rows**:
- Top: Character embedding (gray PEs)
- Middle: LSTM hidden state (blue PEs)
- Bottom: Argmax/Next char (pink PEs)
- **Columns**: 16 PEs per row (total 48 PEs).
- **Active Links**: Green lines connecting PEs.
#### Bar Chart (c)
- **X-Axis**: Model configurations (Ideal weights, ODP, TDP).
- **Y-Axis**: Bits per character (1.0–1.5).
- **Legend**:
- **FP software baseline**: Black
- **Quantization model**: Pink
- **Weight noise model**: Orange
- **Weight noise + quantization**: Blue
- **Chip experiment**: Green
### Detailed Analysis
#### Neural Network (a)
- **Flow**:
1. Input text is embedded into character vectors.
2. Processed through input and hidden gates (matrix multiplications).
3. Output layer produces logits for the next character.
4. Argmax selects the most probable character.
#### IBM HERMES Project Chip (b)
- **Hardware Structure**:
- **Character Embedding Row**: 16 PEs (gray) handle input encoding.
- **LSTM Hidden State Row**: 16 PEs (blue) compute hidden states.
- **Argmax/Next Char Row**: 16 PEs (pink) perform final prediction.
- **Active Connections**: Green lines indicate active data paths between PEs during computation.
#### Bar Chart (c)
- **Data Points**:
| Model Configuration | Ideal Weights | ODP | TDP |
|---------------------------|---------------|--------|--------|
| FP software baseline | 1.336 | — | — |
| Quantization model | 1.358 | — | — |
| Weight noise model | 1.412 | 1.439 | 1.456 |
| Weight noise + quantization | 1.383 | 1.406 | 1.433 |
| Chip experiment | — | — | 1.433 |
### Key Observations
1. **Bar Chart Trends**:
- **FP software baseline** (black) has the lowest bits per character (1.336) under "Ideal weights."
- **Chip experiment** (green) achieves 1.433 bits per character under "TDP," outperforming other models in this configuration.
- **Weight noise + quantization** (blue) shows moderate performance (1.406 bits under TDP).
- **Weight noise model** (orange) has the highest bits per character (1.456 under ODP).
2. **Neural Network/Chip Relationship**:
- The chip implementation mirrors the neural network's architecture, with dedicated rows for embeddings, hidden states, and output.
- Active links (green) suggest optimized on-chip communication for sequential processing.
### Interpretation
- **Efficiency Gains**: The chip experiment reduces bits per character compared to software baselines, suggesting hardware acceleration improves efficiency.
- **Model Robustness**: Adding weight noise degrades performance (higher bits per character), but quantization mitigates this effect.
- **Hardware-Software Alignment**: The chip's grid structure directly maps to the neural network's layers, enabling parallel processing of embeddings, hidden states, and output.
- **Anomaly**: The "Chip experiment" lacks data for "Ideal weights" and "ODP," implying it was only tested under "TDP" conditions.
This analysis demonstrates how hardware-software co-design (e.g., the IBM HERMES chip) can optimize neural network performance, balancing accuracy and resource efficiency.