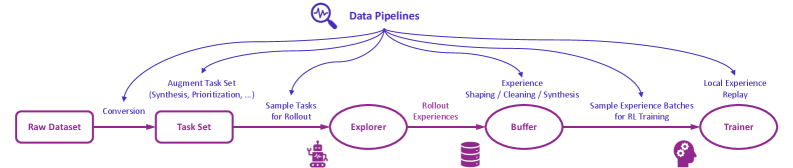
## Flowchart: Data Pipeline Architecture
### Overview
The diagram illustrates a multi-stage data pipeline for processing raw datasets into trained models, with feedback loops for iterative improvement. Key components include data conversion, task sampling, experience exploration, buffering, and model training.
### Components/Axes
- **Components**:
- **Raw Dataset** (leftmost box)
- **Task Set** (conversion from Raw Dataset)
- **Explorer** (processes sampled tasks)
- **Buffer** (stores rollout experiences)
- **Trainer** (uses experience batches for training)
- **Arrows/Labels**:
- "Conversion" (Raw Dataset → Task Set)
- "Sample Tasks for Rollout" (Task Set → Explorer)
- "Rollout Experiences" (Explorer → Buffer)
- "Experience Shaping / Cleaning / Synthesis" (Buffer → Trainer)
- "Sample Experience Batches for RL Training" (Buffer → Trainer)
- "Local Experience Replay" (Trainer → Buffer)
- **Legend**:
- "Data Pipelines" (magnifying glass icon at the top)
### Detailed Analysis
1. **Raw Dataset → Task Set**:
- Raw data is converted into a structured task set via synthesis and prioritization.
2. **Task Set → Explorer**:
- Tasks are sampled for rollout, implying iterative testing or simulation.
3. **Explorer → Buffer**:
- The Explorer generates "Rollout Experiences," which are stored in the Buffer.
4. **Buffer → Trainer**:
- Experiences are shaped, cleaned, and synthesized before being sampled as batches for reinforcement learning (RL) training.
5. **Trainer → Buffer**:
- A feedback loop ("Local Experience Replay") sends trained experiences back to the Buffer for reuse.
### Key Observations
- **Sequential Flow**: Data progresses linearly from Raw Dataset to Trainer, with a critical feedback loop from Trainer to Buffer.
- **Iterative Refinement**: The Buffer acts as a reservoir for experiences, enabling continuous improvement through replay.
- **Modular Design**: Each component (Explorer, Buffer, Trainer) has distinct responsibilities, suggesting a modular architecture.
### Interpretation
This pipeline emphasizes **closed-loop learning**, where the Trainer not only processes experiences but also replays them locally to refine future iterations. The Buffer’s role as a central hub for experience storage and preprocessing highlights its importance in managing data quality and diversity. The feedback loop ensures that the system adapts dynamically, leveraging past experiences to improve future training cycles.
**Notable Patterns**:
- The use of "Local Experience Replay" suggests a focus on efficiency and reducing reliance on external data sources.
- The separation of "Experience Shaping/Cleaning/Synthesis" implies rigorous preprocessing to enhance training stability.
**Underlying Logic**:
The diagram aligns with reinforcement learning principles, where agents learn through interaction (rollout experiences) and refine policies via experience replay. The modular components suggest scalability, allowing each stage to be optimized independently.