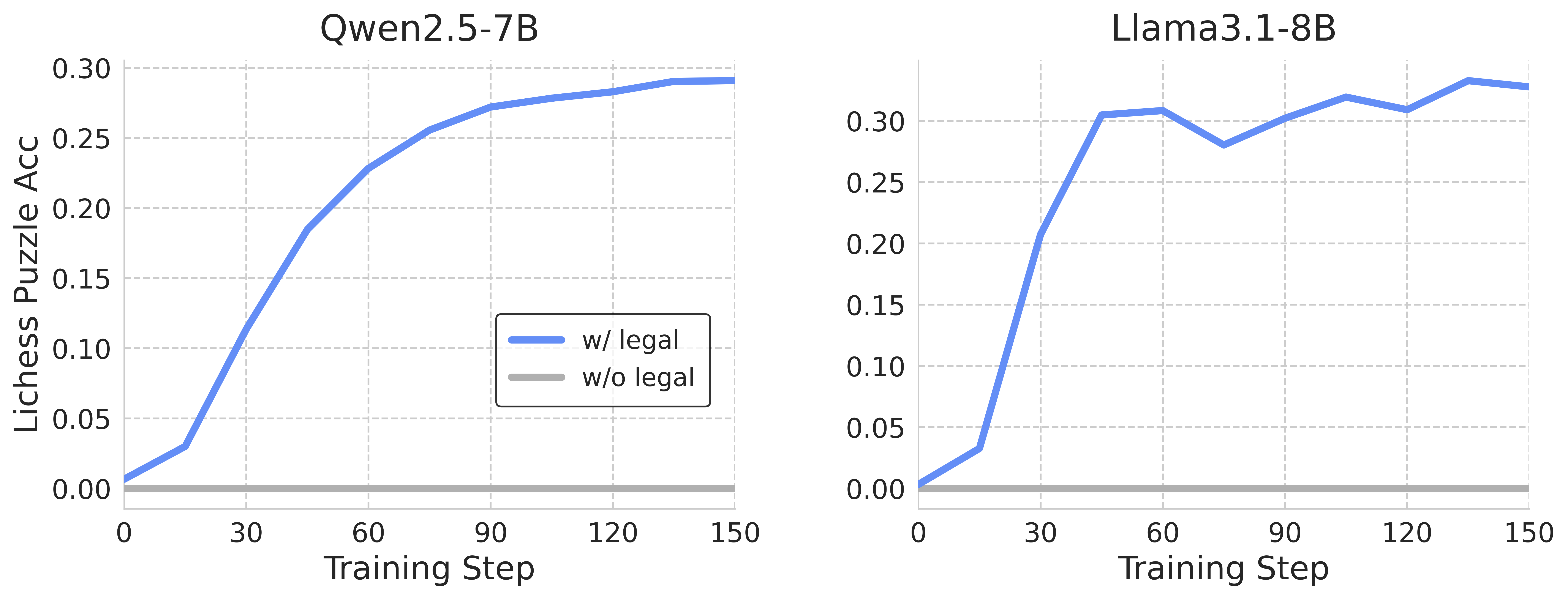
## Line Graphs: Chess Puzzle Accuracy vs. Training Step for Two Language Models
### Overview
The image presents two line graphs comparing the performance of two language models, Qwen2.5-7B and Llama3.1-8B, on a chess puzzle accuracy task. Each graph plots the accuracy (Lichess Puzzle Acc) against the training step. Two data series are shown for each model: one representing performance with legal move constraints ("w/ legal") and the other without ("w/o legal").
### Components/Axes
* **Titles:**
* Left Graph: Qwen2.5-7B
* Right Graph: Llama3.1-8B
* **Y-axis (Lichess Puzzle Acc):**
* Label: "Lichess Puzzle Acc"
* Scale: 0.00 to 0.30, with increments of 0.05 (0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30)
* **X-axis (Training Step):**
* Label: "Training Step"
* Scale: 0 to 150, with increments of 30 (0, 30, 60, 90, 120, 150)
* **Legend (Position: Center-Right, between the two graphs):**
* Blue line: "w/ legal"
* Gray line: "w/o legal"
### Detailed Analysis
**Left Graph: Qwen2.5-7B**
* **"w/ legal" (Blue):** The line starts at approximately 0.01 at training step 0. It increases sharply to approximately 0.12 by step 30, then to approximately 0.23 by step 60. The increase slows down, reaching approximately 0.27 by step 90, and approximately 0.29 by step 120, and remains relatively stable at approximately 0.29 by step 150.
* **"w/o legal" (Gray):** The line remains consistently at approximately 0.00 across all training steps (0 to 150).
**Right Graph: Llama3.1-8B**
* **"w/ legal" (Blue):** The line starts at approximately 0.00 at training step 0. It increases sharply to approximately 0.30 by step 30, then dips slightly to approximately 0.28 by step 60. It then increases to approximately 0.31 by step 90, dips again to approximately 0.30 by step 120, and ends at approximately 0.29 by step 150.
* **"w/o legal" (Gray):** The line remains consistently at approximately 0.00 across all training steps (0 to 150).
### Key Observations
* Both models show a significant increase in chess puzzle accuracy with legal move constraints ("w/ legal") as the training step increases.
* The "w/o legal" data series for both models remains at a near-zero accuracy level throughout the training process.
* Llama3.1-8B reaches a higher accuracy level earlier in the training process compared to Qwen2.5-7B.
* Llama3.1-8B's accuracy fluctuates more than Qwen2.5-7B's accuracy as the training step increases.
### Interpretation
The data suggests that both language models benefit significantly from training with legal move constraints when solving chess puzzles. The "w/o legal" data series indicates that without these constraints, the models are unable to achieve any meaningful accuracy. Llama3.1-8B appears to learn faster initially but exhibits more variability in its performance compared to Qwen2.5-7B. The difference in performance between the two models could be attributed to differences in their architecture, training data, or other hyperparameters. The graphs highlight the importance of legal move constraints in training language models for chess-related tasks.