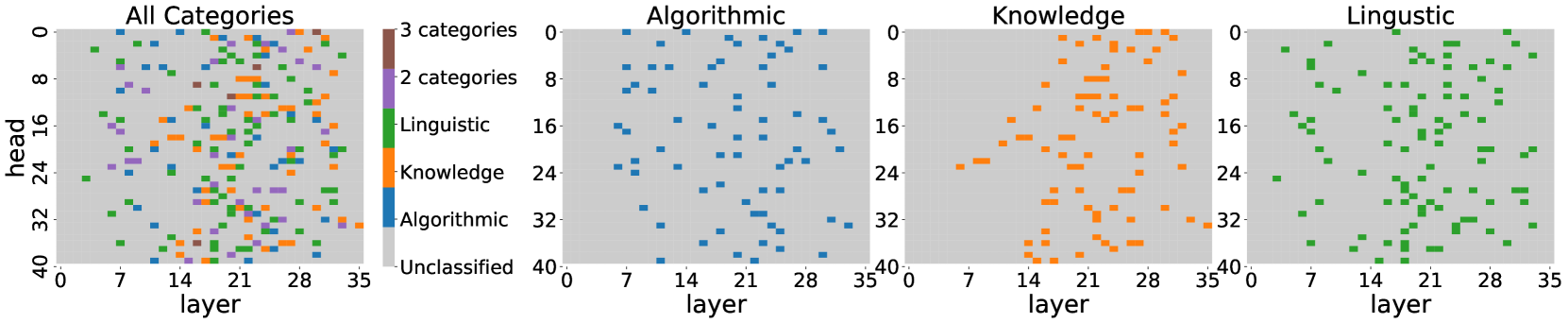
## Heatmap: Category Distribution Across Layers and Heads
### Overview
The image consists of four heatmaps arranged horizontally. Each heatmap visualizes the distribution of categories across different layers and heads of a model. The first heatmap, "All Categories," shows the combined distribution of all categories, while the subsequent heatmaps ("Algorithmic," "Knowledge," and "Linguistic") display the distribution of individual categories. The heatmaps share the same axes: "layer" on the x-axis and "head" on the y-axis. A legend is provided next to the "All Categories" heatmap to indicate the color-coding for each category.
### Components/Axes
* **X-axis (Layer):** Represents the layer number, ranging from 0 to 35, with tick marks at intervals of 7.
* **Y-axis (Head):** Represents the head number, ranging from 0 to 40, with tick marks at intervals of 8.
* **Heatmaps:** Each heatmap is a grid of cells, where each cell's color indicates the category or combination of categories present at a specific layer and head.
* **Legend (Located to the right of the "All Categories" heatmap):**
* **Brown:** "3 categories"
* **Purple:** "2 categories"
* **Green:** "Linguistic"
* **Orange:** "Knowledge"
* **Blue:** "Algorithmic"
* **Light Gray:** "Unclassified"
### Detailed Analysis
**1. All Categories Heatmap:**
* This heatmap shows a mix of all categories.
* There are regions with single categories, combinations of two categories (purple), and combinations of three categories (brown).
* The distribution appears relatively uniform across layers and heads, with some concentrations of specific categories in certain areas.
**2. Algorithmic Heatmap:**
* This heatmap shows the distribution of the "Algorithmic" category (blue).
* The "Algorithmic" category is sparsely distributed across layers and heads.
* There are no clear patterns or concentrations of the "Algorithmic" category.
**3. Knowledge Heatmap:**
* This heatmap shows the distribution of the "Knowledge" category (orange).
* The "Knowledge" category is more concentrated in the middle layers (around layer 16 to 32) and heads (around head 8 to 24).
* There are fewer instances of the "Knowledge" category in the earlier and later layers.
**4. Linguistic Heatmap:**
* This heatmap shows the distribution of the "Linguistic" category (green).
* The "Linguistic" category is distributed across layers and heads, with some concentrations in the earlier layers (around layer 0 to 16).
* There are fewer instances of the "Linguistic" category in the later layers.
### Key Observations
* The "All Categories" heatmap provides an overview of the combined distribution of all categories.
* The "Algorithmic" category is sparsely distributed.
* The "Knowledge" category is concentrated in the middle layers and heads.
* The "Linguistic" category is concentrated in the earlier layers.
* The "Unclassified" category is not explicitly shown in its own heatmap, but its presence can be inferred from the "All Categories" heatmap in areas where no other categories are present.
### Interpretation
The heatmaps visualize the distribution of different categories across the layers and heads of a model. The distribution patterns suggest that different layers and heads may be specialized for processing different types of information. For example, the concentration of the "Knowledge" category in the middle layers and heads may indicate that these layers are responsible for processing knowledge-related information. Similarly, the concentration of the "Linguistic" category in the earlier layers may indicate that these layers are responsible for processing linguistic information. The sparse distribution of the "Algorithmic" category may suggest that this category is less important for the model's overall performance. The presence of combinations of categories in the "All Categories" heatmap indicates that some layers and heads may be involved in processing multiple types of information.