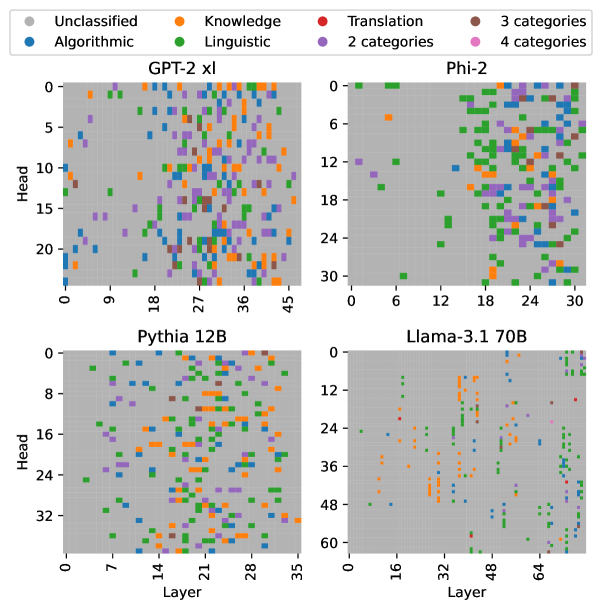
## Heatmap: Category Distribution Across Model Layers and Heads
### Overview
The image presents a series of heatmaps visualizing the distribution of different categories across the layers and heads of four different language models: GPT-2 xl, Phi-2, Pythia 12B, and Llama-3.1 70B. Each heatmap represents a model, with the y-axis indicating the "Head" and the x-axis indicating the "Layer". The color of each cell represents a category, as defined in the legend.
### Components/Axes
* **Title:** Category Distribution Across Model Layers and Heads
* **Heatmaps:** Four heatmaps, one for each model: GPT-2 xl, Phi-2, Pythia 12B, and Llama-3.1 70B.
* **Y-axis (Head):** Represents the attention heads within each layer.
* GPT-2 xl: Ranges from 0 to 24, incrementing by 5.
* Phi-2: Ranges from 0 to 30, incrementing by 6.
* Pythia 12B: Ranges from 0 to 32, incrementing by 8.
* Llama-3.1 70B: Ranges from 0 to 60, incrementing by 12.
* **X-axis (Layer):** Represents the layers of the model.
* GPT-2 xl: Ranges from 0 to 45, incrementing by 9.
* Phi-2: Ranges from 0 to 30, incrementing by 6.
* Pythia 12B: Ranges from 0 to 35, incrementing by 7.
* Llama-3.1 70B: Ranges from 0 to 64, incrementing by 16.
* **Legend (Top-Left):**
* Gray: Unclassified
* Blue: Algorithmic
* Orange: Knowledge
* Green: Linguistic
* Red: Translation
* Purple: 2 categories
* Brown: 3 categories
* Pink: 4 categories
### Detailed Analysis
**1. GPT-2 xl (Top-Left)**
* X-axis (Layer): 0 to 45, incrementing by 9.
* Y-axis (Head): 0 to 20, incrementing by 5.
* Trend: The categories are distributed somewhat evenly across the layers, with a higher concentration of "Knowledge" (orange) and "Linguistic" (green) categories in the middle layers (around layer 18-36). "Algorithmic" (blue) is scattered throughout.
* Data Points:
* Head 0, Layer 0: Unclassified (gray)
* Head 0, Layer 9: Algorithmic (blue)
* Head 5, Layer 18: Knowledge (orange)
* Head 10, Layer 27: Linguistic (green)
* Head 15, Layer 36: 2 categories (purple)
* Head 20, Layer 45: Unclassified (gray)
**2. Phi-2 (Top-Right)**
* X-axis (Layer): 0 to 30, incrementing by 6.
* Y-axis (Head): 0 to 30, incrementing by 6.
* Trend: The categories are more concentrated in the later layers (around layer 18-30). "Linguistic" (green) is the dominant category.
* Data Points:
* Head 0, Layer 0: Unclassified (gray)
* Head 0, Layer 6: Knowledge (orange)
* Head 6, Layer 12: Unclassified (gray)
* Head 12, Layer 18: Linguistic (green)
* Head 18, Layer 24: Linguistic (green)
* Head 24, Layer 30: Linguistic (green)
* Head 30, Layer 30: Unclassified (gray)
**3. Pythia 12B (Bottom-Left)**
* X-axis (Layer): 0 to 35, incrementing by 7.
* Y-axis (Head): 0 to 32, incrementing by 8.
* Trend: The categories are distributed relatively evenly across the layers and heads. "Knowledge" (orange) and "Linguistic" (green) are present throughout.
* Data Points:
* Head 0, Layer 0: Unclassified (gray)
* Head 0, Layer 7: 2 categories (purple)
* Head 8, Layer 14: Knowledge (orange)
* Head 16, Layer 21: Knowledge (orange)
* Head 24, Layer 28: 3 categories (brown)
* Head 32, Layer 35: Linguistic (green)
**4. Llama-3.1 70B (Bottom-Right)**
* X-axis (Layer): 0 to 64, incrementing by 16.
* Y-axis (Head): 0 to 60, incrementing by 12.
* Trend: The categories are sparsely distributed. "Knowledge" (orange) and "Linguistic" (green) are present, but less concentrated than in other models.
* Data Points:
* Head 0, Layer 0: Unclassified (gray)
* Head 0, Layer 16: Unclassified (gray)
* Head 12, Layer 32: Algorithmic (blue)
* Head 24, Layer 48: Knowledge (orange)
* Head 36, Layer 64: Linguistic (green)
* Head 48, Layer 64: Unclassified (gray)
* Head 60, Layer 64: Unclassified (gray)
### Key Observations
* **Category Distribution:** The distribution of categories varies significantly across the four models.
* **Dominant Categories:** "Knowledge" (orange) and "Linguistic" (green) appear to be important categories for all models, but their concentration varies.
* **Sparse Distribution:** Llama-3.1 70B shows a sparser distribution of categories compared to the other models.
* **Layer Concentration:** Phi-2 shows a concentration of categories in the later layers.
### Interpretation
The heatmaps provide insights into how different language models distribute various categories of information across their layers and heads. The varying distributions suggest that each model learns and processes information differently. The concentration of "Knowledge" and "Linguistic" categories highlights their importance in language modeling. The sparse distribution in Llama-3.1 70B could indicate a more distributed representation of information or a different learning strategy. The concentration of categories in the later layers of Phi-2 might suggest that these layers are responsible for higher-level reasoning or language understanding. Further analysis would be needed to understand the specific roles of each category and how they contribute to the overall performance of the models.