\n
## Scatter Plots: Category Distribution Across Model Layers and Heads
### Overview
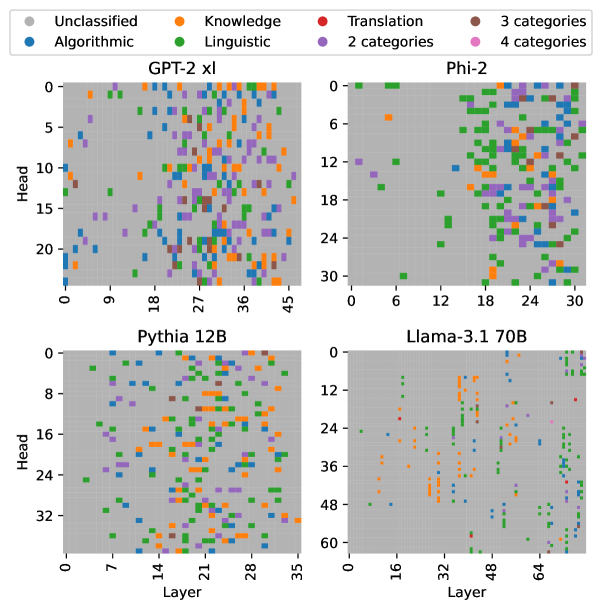
The image presents four scatter plots, each representing a different large language model (GPT-2 XL, Phi-2, Pythia 12B, and Llama-3.1 70B). Each plot visualizes the distribution of different categories of information processed by the model's layers and heads. The x-axis represents the layer number, and the y-axis represents the head number. Each point on the plot is colored according to the category of information it represents.
### Components/Axes
* **X-axis (Layer):** Represents the layer number within the neural network. Scales vary for each model:
* GPT-2 XL: 0 to 45
* Phi-2: 0 to 30
* Pythia 12B: 0 to 35
* Llama-3.1 70B: 0 to 64
* **Y-axis (Head):** Represents the head number within the neural network. Scales vary for each model:
* GPT-2 XL: 0 to 20
* Phi-2: 0 to 30
* Pythia 12B: 0 to 32
* Llama-3.1 70B: 0 to 60
* **Legend:** Located at the top-left of the image, defining the color-coding for each category:
* Grey: Unclassified
* Blue: Algorithmic
* Orange: Knowledge
* Green: Linguistic
* Red: Translation
* Purple: 3 categories
* Light Purple: 2 categories
* Dark Purple: 4 categories
### Detailed Analysis or Content Details
**GPT-2 XL (Top-Left):**
* The plot shows a relatively even distribution of all categories across layers and heads.
* Algorithmic (blue) and Linguistic (green) categories appear to be the most prevalent, with a slight concentration in the lower layer numbers (0-20) and across most head numbers.
* Knowledge (orange) is scattered throughout, with a higher density in the middle layers (18-36).
* Unclassified (grey) points are present but less frequent.
* Translation (red) and the category counts (purple shades) are sparsely distributed.
**Phi-2 (Top-Right):**
* A significant concentration of Linguistic (green) points is observed in the upper layers (18-30) and across most head numbers.
* Algorithmic (blue) points are more concentrated in the lower layers (0-12) and lower head numbers.
* Knowledge (orange) is scattered, with a slight concentration in the middle layers (12-24).
* Translation (red) and the category counts (purple shades) are sparsely distributed.
**Pythia 12B (Bottom-Left):**
* Linguistic (green) points dominate the lower layers (0-14) and are distributed across most head numbers.
* Knowledge (orange) points are concentrated in the middle layers (14-28).
* Algorithmic (blue) points are scattered throughout, with a higher density in the lower layers.
* Unclassified (grey) points are present but less frequent.
* Translation (red) and the category counts (purple shades) are sparsely distributed.
**Llama-3.1 70B (Bottom-Right):**
* Linguistic (green) points are heavily concentrated in the upper layers (32-64) and across most head numbers.
* Knowledge (orange) points are concentrated in the middle layers (16-48).
* Algorithmic (blue) points are scattered throughout, with a higher density in the lower layers.
* Unclassified (grey) points are present but less frequent.
* Translation (red) and the category counts (purple shades) are sparsely distributed.
### Key Observations
* The distribution of categories varies significantly across different models.
* Linguistic information appears to be predominantly processed in the upper layers of Phi-2 and Llama-3.1 70B.
* Knowledge information is often concentrated in the middle layers across all models.
* Algorithmic information is more evenly distributed, but tends to be more prevalent in the lower layers.
* The "Unclassified" category suggests that some information processed by the models does not fall neatly into the defined categories.
* The category counts (2, 3, and 4 categories) are very sparsely distributed across all models.
### Interpretation
These scatter plots provide insights into how different large language models process information at various layers and heads. The varying distributions suggest that each model has a unique architecture and learning strategy. The concentration of Linguistic information in the upper layers of Phi-2 and Llama-3.1 70B might indicate that these models prioritize language understanding and generation in their later stages of processing. The concentration of Knowledge in the middle layers suggests that these layers are crucial for integrating and reasoning about factual information. The presence of the "Unclassified" category highlights the complexity of natural language and the limitations of current categorization schemes. The sparse distribution of the category counts suggests that these are less common or more nuanced types of information processing.
The plots demonstrate a clear relationship between model architecture, layer depth, and the types of information processed. By visualizing this relationship, we can gain a better understanding of the inner workings of these powerful language models and potentially improve their design and performance. The differences between the models suggest that there isn't a single "best" way to process language, and that different architectures may be better suited for different tasks.