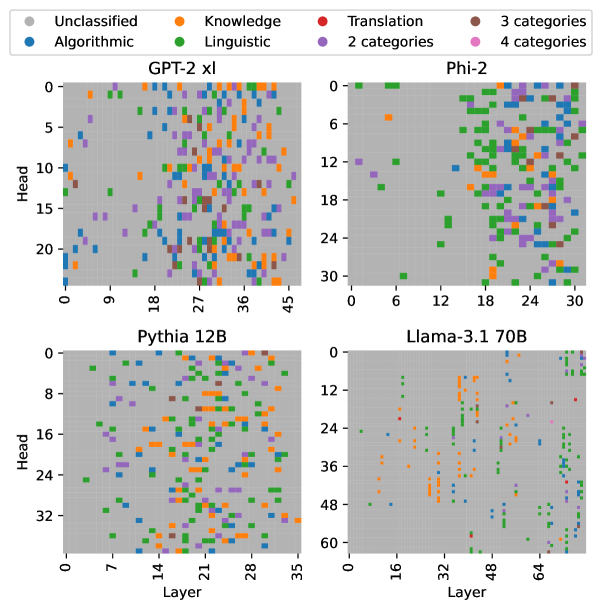
## Heatmap: Distribution of Linguistic and Knowledge Categories Across Model Layers and Heads
### Overview
The image presents four heatmaps comparing the distribution of linguistic and knowledge-related categories across different neural network models (GPT-2 xl, Phi-2, Pythia 12B, Llama-3.1 70B). Each panel visualizes the relationship between **layers** (x-axis) and **heads** (y-axis), with colored squares representing categories such as "Unclassified," "Knowledge," "Translation," "Linguistic," and numerical categories (2, 3, 4). The legend in the top-left corner maps colors to these categories.
---
### Components/Axes
- **X-axis (Layer)**:
- Labeled "Layer" with numerical ranges:
- GPT-2 xl: 0–45
- Phi-2: 0–30
- Pythia 12B: 0–32
- Llama-3.1 70B: 0–60
- **Y-axis (Head)**:
- Labeled "Head" with numerical ranges:
- GPT-2 xl: 0–20
- Phi-2: 0–24
- Pythia 12B: 0–32
- Llama-3.1 70B: 0–48
- **Legend**:
- **Colors**:
- Gray: Unclassified
- Orange: Knowledge
- Red: Translation
- Green: Linguistic
- Purple: 2 categories
- Pink: 4 categories
- **Text**: "3 categories" and "4 categories" are noted but not explicitly tied to specific colors.
---
### Detailed Analysis
#### GPT-2 xl (Top-Left)
- **Layer range**: 0–45, **Head range**: 0–20.
- **Color distribution**:
- **Orange (Knowledge)**: Scattered across layers 0–45, with higher density in mid-layers (e.g., layers 10–20).
- **Green (Linguistic)**: Concentrated in upper layers (e.g., layers 30–45).
- **Red (Translation)**: Sparse, with isolated clusters in lower layers (e.g., layers 5–10).
- **Gray (Unclassified)**: Dominates lower layers (0–10) and some mid-layers.
#### Phi-2 (Top-Right)
- **Layer range**: 0–30, **Head range**: 0–24.
- **Color distribution**:
- **Green (Linguistic)**: Dominates upper layers (e.g., layers 15–30), forming dense clusters.
- **Orange (Knowledge)**: Scattered in lower layers (0–15), with fewer instances.
- **Red (Translation)**: Minimal, concentrated in mid-layers (e.g., layers 10–20).
- **Gray (Unclassified)**: Sparse, mostly in lower layers.
#### Pythia 12B (Bottom-Left)
- **Layer range**: 0–32, **Head range**: 0–32.
- **Color distribution**:
- **Orange (Knowledge)**: Dense in lower layers (0–10), with gradual decline in higher layers.
- **Green (Linguistic)**: Scattered throughout, with no clear pattern.
- **Red (Translation)**: Minimal, with isolated points in mid-layers.
- **Gray (Unclassified)**: Dominates upper layers (20–32).
#### Llama-3.1 70B (Bottom-Right)
- **Layer range**: 0–60, **Head range**: 0–48.
- **Color distribution**:
- **Red (Translation)**: Concentrated in upper layers (e.g., layers 40–60), forming dense clusters.
- **Green (Linguistic)**: Scattered in mid-layers (e.g., layers 20–40).
- **Orange (Knowledge)**: Sparse, with isolated points in lower layers.
- **Gray (Unclassified)**: Minimal, mostly in lower layers.
---
### Key Observations
1. **Model-specific patterns**:
- **Phi-2** and **Llama-3.1 70B** show strong specialization in **Linguistic** (green) and **Translation** (red) categories, respectively, in higher layers.
- **Pythia 12B** exhibits a more uniform distribution of **Knowledge** (orange) in lower layers, suggesting less task-specific specialization.
- **GPT-2 xl** has a balanced mix of categories, with **Knowledge** and **Linguistic** dominating mid-layers.
2. **Unclassified (gray) dominance**:
- Lower layers across all models show higher gray (Unclassified) density, indicating potential ambiguity in early processing stages.
3. **Color-category alignment**:
- All colors in the panels match the legend (e.g., orange = Knowledge, green = Linguistic).
---
### Interpretation
The heatmaps reveal how different models allocate computational resources (layers and heads) to specific linguistic or knowledge tasks.
- **Specialization**: Models like Phi-2 and Llama-3.1 70B demonstrate clear task-specific layering (e.g., Linguistic in Phi-2, Translation in Llama-3.1 70B), suggesting optimized architectures for these functions.
- **Generalization**: GPT-2 xl’s mixed distribution implies a more generalized approach, with overlapping roles across layers.
- **Unclassified regions**: The prevalence of gray in lower layers may reflect unresolved or ambiguous processing, highlighting areas for further research.
The data underscores the trade-off between specialization and generalization in neural architectures, with larger models (e.g., Llama-3.1 70B) showing more pronounced task-specific patterns. This could inform future model design for targeted applications like translation or linguistic analysis.