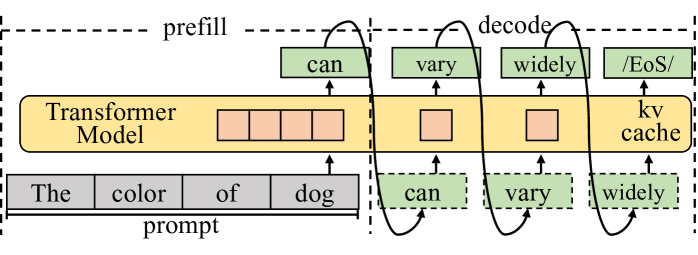
## Diagram: Transformer Model Prefill and Decode
### Overview
The image illustrates the prefill and decode stages of a transformer model, showing the flow of information between the prompt, the transformer model with its kv cache, and the generated output.
### Components/Axes
* **Regions:** The diagram is divided into two main regions: "prefill" (left) and "decode" (right), separated by a vertical dashed line. The entire diagram is enclosed in a larger dashed rectangle.
* **Transformer Model:** A yellow rounded rectangle labeled "Transformer Model" with "kv cache" below it.
* **Prompt:** A series of gray rectangles labeled "The", "color", "of", and "dog" with the label "prompt" below.
* **Output:** Green rectangles representing the generated words: "can", "vary", "widely", and "/EoS/". These appear both above and below the Transformer Model.
* **Arrows:** Black curved arrows indicate the flow of information.
### Detailed Analysis
* **Prefill Stage (Left):**
* The "prompt" consists of the words "The", "color", "of", and "dog".
* These words are fed into the "Transformer Model".
* Inside the "Transformer Model", there are four orange squares, representing the processing of the input.
* **Decode Stage (Right):**
* The "Transformer Model" contains the "kv cache".
* The model generates the words "can", "vary", and "widely", and "/EoS/".
* The generated words are fed back into the "Transformer Model" to influence the generation of subsequent words.
* The arrows show the feedback loop from the generated words to the "kv cache" and then back to the output.
* The "kv cache" contains one orange square for each word generated.
### Key Observations
* The diagram highlights the iterative nature of the decoding process in transformer models.
* The "kv cache" is used to store information from previous steps, allowing the model to maintain context.
* The "prefill" stage processes the initial prompt, while the "decode" stage generates the output sequence.
### Interpretation
The diagram illustrates how a transformer model processes an input prompt and generates a sequence of words. The "prefill" stage initializes the model with the prompt, and the "decode" stage iteratively generates the output, using the "kv cache" to maintain context. The feedback loop in the "decode" stage allows the model to condition its output on previously generated words, leading to coherent and contextually relevant sequences. The "/EoS/" likely stands for "End of Sequence", indicating the termination of the generation process.