\n
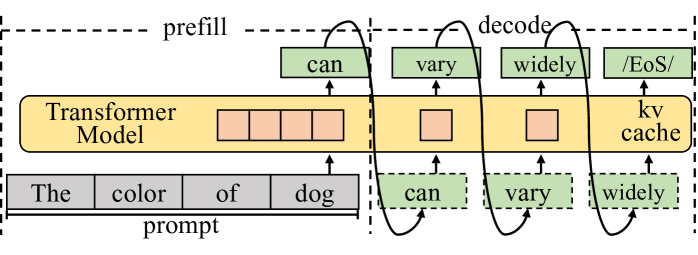
## Diagram: Transformer Model Prefill and Decode Process
### Overview
The image is a diagram illustrating the prefill and decode stages of a Transformer model. It depicts how a prompt is processed and how the model generates subsequent tokens. The diagram highlights the use of a "kv cache" during the decode phase.
### Components/Axes
The diagram consists of the following components:
* **Transformer Model:** A large yellow rectangular block labeled "Transformer Model".
* **Prompt:** A gray rectangular block labeled "prompt" containing the words "The", "color", "of", and "dog".
* **Prefill Stage:** A dashed box encompassing the initial processing of the prompt. Labeled "prefill".
* **Decode Stage:** A dashed box encompassing the iterative generation of tokens. Labeled "decode".
* **kv cache:** A yellow rectangular block labeled "kv cache".
* **Generated Tokens:** Green boxes labeled "can", "vary", and "widely".
* **End of Sequence Token:** A green box labeled "EoS/".
* **Arrows:** Curved arrows indicating the flow of information between the prompt, the Transformer Model, and the generated tokens.
### Detailed Analysis or Content Details
The diagram shows the following process:
1. **Prefill:** The prompt ("The color of dog") is fed into the Transformer Model. The model processes this prompt and generates the first token, "can". This token is then added to the sequence.
2. **Decode:** The process iterates. The model takes the original prompt *and* the previously generated token ("can") as input and generates the next token, "vary". This continues with "vary" and "widely".
3. **kv cache:** The "kv cache" is used during the decode stage. It stores information from previous computations, allowing the model to efficiently generate subsequent tokens without recomputing everything from scratch.
4. **Token Generation:** Each generated token ("can", "vary", "widely") is shown in a green box and is fed back into the Transformer Model for the next iteration of the decode stage.
5. **End of Sequence:** The diagram indicates that the process can terminate with the generation of an "EoS/" (End of Sequence) token.
### Key Observations
* The diagram emphasizes the iterative nature of the decode stage.
* The "kv cache" is a crucial component for efficient decoding.
* The diagram visually represents how the model builds upon the initial prompt to generate a sequence of tokens.
### Interpretation
This diagram illustrates the core mechanism of autoregressive language models like Transformers. The prefill stage establishes an initial context based on the prompt, and the decode stage iteratively expands upon this context to generate coherent text. The "kv cache" is a key optimization that allows for efficient generation of long sequences. The diagram highlights the sequential dependency of each generated token on the preceding tokens and the original prompt. The use of dashed boxes to delineate "prefill" and "decode" suggests these are distinct phases in the model's operation, with the decode phase relying on the output of the prefill phase and the "kv cache". The diagram is a simplified representation of a complex process, but it effectively conveys the fundamental principles of Transformer-based language generation.